Что такое кластер серверов. Кластерная структура сервера
Кластер серверов 1С:Предприятия 8 (1C:Enterprise 8 Server Cluster)
Кластер серверов 1С:Предприятия 8 является основным компонентом платформы, который обеспечивает взаимодействие между системой управления базами данных и пользователем в случае варианта клиент-серверной работы. Кластер дает возможность организовать бесперебойную, устойчивую к отказам, конкурентную работу для значительного количества пользователей с объемными информационными базами.
Кластер серверов 1С:Предприятия 8 – это логическое понятие, которое обозначает совокупность процессов, которые обслуживают один и тот же комплект информационных баз.
Можно выделить следующие возможности кластера серверов, как основные:
- возможность функционировать как на нескольких, так и на одном компьютере (рабочих серверах);
- каждый рабочий сервер может поддерживать функционирование как одного, так и нескольких рабочих процессов, которые обслуживают клиентские соединения в границах этого кластера;
- включение новых клиентов в рабочие процессы кластера происходит, основываясь на долгосрочном анализе статистики загруженности рабочих процессов;
- взаимодействие всех процессов кластера между собой, с клиентскими приложениями и сервером баз данных осуществляется по протоколу TCP/IP;
- запущены процессы кластера, могут быть как сервис, так и как приложение
Клиент-серверный вариант. Схема работы
При этом варианте работы с сервером взаимодействует клиентское приложение. Кластер серверов, в свою очередь, взаимодействует с сервером баз данных.
Роль центрального сервера кластеров играет один из компьютеров, которые входят в состав кластера серверов. Кроме того, что центральный сервер обслуживает клиентские соединения, он еще управляет работой, в целом, всего кластера и хранит реестр данного кластера.
Кластер адресуется для клиентского соединения по имени центрального сервера и, возможно, номеру сетевого порта. В случае если сетевой порт используется стандартный, то для соединения хватает просто указать имя центрального сервера.
Во время установки соединения к центральному серверу кластера обращается клиентское приложение. Основываясь на анализе статистики загруженности рабочих процессов, центральный сервер переправляет клиентское приложение к необходимому рабочему процессу, который должен его обслуживать. Данный процесс может быть активирован на любом рабочем сервере кластера, в частности и на центральном сервере.
Обслуживание соединения и аутентификация пользователя поддерживаются этим рабочим процессом до момента прекращение работы клиента с конкретной информационной базой.
Кластер серверов
Элементарный кластер серверов может представлять собой единственный компьютер и содержать только один рабочий процесс.
На рисунке можно наблюдать все элементы, которые, так или иначе, принимают участие в работе кластера серверов. Это следующие элементы:
- процессы кластера серверов:
o ragent.exe;
o rmngr.exe;
o rphost.exe; - хранилища данных:
o список кластеров;
o реестр кластера.
Процесс ragent.exe, называемый – агент сервера, обеспечивает функционирование компьютера как составной части кластера. Следовательно, компьютер, на котором запущен процесс ragent.exe, следует называть рабочим сервером. В частности одной из функциональных обязанностей ragent.exe является ведение реестра кластеров, которые находятся на конкретном рабочем сервере.
Ни реестр кластеров, ни агент сервера не являются составной частью кластера серверов, а только лишь дают возможность функционировать серверу и кластерам, расположенным на нем.
Сам кластер серверов состоит из таких элементов:
- один или несколько процессов rmngr.exe
- реестр кластера
- один или несколько процессов rphost.exe.
Менеджер кластера (процесс rmngr.exe). Он служит для управления функционирования всего кластера. В состав кластера может входить несколько процессов rmngr.exe, один их которых всегда будет главным менеджером данного кластера, а остальные процессы – дополнительными менеджерами. Центральным сервером кластера следует называть рабочий сервер, на котором действует главный менеджер кластера, и который содержит список кластера. Именно ведение реестра кластера является одной из функций главного менеджера кластера.
Рабочий процесс (процесс rphost.exe). Именно он, непосредственно, обслуживает клиентские приложения, взаимодействуя с сервером баз данных. В этом процессе могут исполняться некоторые процедуры конфигурации серверных модулей.
Масштабируемость 1С версии 8.3
Масштабируемость кластера серверов осуществляется следующими способами:
- увеличивают количество менеджеров в кластере и распределение сервисов между ними
- увеличивают количество рабочих процессов, которые функционируют на данном рабочем сервере
- увеличивают количество рабочих серверов, из которых состоит кластер.
Использование одновременно нескольких менеджеров.
Функции, которые исполняет менеджер кластера, разделяются на несколько сервисов. Данные сервисы можно назначить разным менеджерам кластера. Это дает возможность равномерно распределить нагрузку по нескольким процессам.
Однако некоторые сервисы могут быть использованы только главным менеджером кластера:
- сервис конфигурации кластера
- сервис управления предметами отладки
- сервис блокировок кластера.
Для прочих сервисов допустимы в назначение произвольные менеджеры кластера:
- сервис журналов регистрации
- сервис блокировки объектов
- сервис заданий
- сервис полнотекстового поиска
- сервис сеансовых данных
- сервис нумерации
- сервис пользовательских настроек
- сервис времени
- сервис транзакционных блокировок.
Использование одновременно нескольких рабочих процессов.
С одной стороны использование нескольких рабочих процессов дает возможность понизить нагрузку каждого конкретного рабочего процесса. С другой стороны, применение нескольких рабочих процессов приводит к более эффективному использованию аппаратных ресурсов рабочего сервера. Более того, процедура запуска нескольких рабочих процессов повышает надежность сервера, так как изолирует группы клиентов, которые работают с разными информационными базами. Рабочий процесс в кластере, в котором допустим запуск нескольких рабочих процессов, может быть перезапущен автоматически, в рамках временного интервала, указанного администратором кластера.
Возможность использования большего количества рабочих процессов (увеличение количества клиентских соединений) не увеличивая нагрузки на конкретный рабочий процесс, дает изменение, в большую сторону, количества рабочих серверов, которые входят в кластер.
Отказоустойчивость 1С версии 8.3
Устойчивость к отказам в работе кластера обеспечивается тремя направлениями:
- резервированием самого кластера
- резервированием рабочих процессов
- устойчивостью к обрыву канала связи.
Резервирование кластера 1С версии 8.3
Несколько кластеров объединяются в группу резервирования. Кластеры, которые находятся в такой группе, автоматически синхронизируются.
В случае выхода из строя активного кластера, его заменяет следующий рабочий кластер группы. После того, как неработоспособный кластер будет восстановлен, он станет активным после синхронизации данных.
Резервирование рабочих процессов 1С версии 8.3
Для каждого из рабочих процессов есть возможность указания вариантов его использования:
- использовать
- не использовать
- использовать как резервный.
В случае аварийного завершения работы какого-либо процесса, кластер начинает использовать вместо него неактивный на данный момент резервный процесс. При этом происходит автоматическое перераспределение имеющейся на него нагрузки.
Устойчивость 1С версии 8.3 к обрыву канала связи
Так как каждому пользователю обеспечивается собственный сеанс связи, то кластер сохраняет данные о подключавшихся пользователях и о том, какие действия ими выполнялись.
При исчезновении физического соединения кластер будет находиться в состоянии ожидания соединения с данным пользователем. В большинстве случаев, после того, как соединение восстановится пользователь будет иметь возможность продолжить работу именно с того места, момента, на котором произошел разрыв связи. Повторное подключение к информационной базе не потребуется.
Сеансы работы в 1С версии 8.3
Сеанс дает возможность определить активного пользователя конкретной информационной базы и определить поток управления от этого клиента. Различают следующие типы сеансов:
- Тонкий клиент, Веб-клиент, Толстый клиент – эти сеансы возникают при обращении соответствующих клиентов к информационной базе
- Соединение типа «Конфигуратор» — оно возникает при обращении к информационной базе конфигуратора
- СОМ-соединение – образовывается при использовании внешнего соединения для обращения к информационной базе
- WS-соединение – возникает в случае обращения к информационной базе веб-сервера, как следствие обращения к опубликованному на веб-сервере Web-сервису
- Фоновое задание – образовывается, когда рабочий процесс кластера обращается к информационной базе. Служит такой сеанс для исполнения кода процедуры фонового задания,
Консоль кластера – создается, когда утилита администрирования клиент-серверного варианта обращается к рабочему процессу - СОМ-администратор – возникает в случае обращения к рабочему процессу с использованием внешнего соединения.
- Работа при использовании различных операционных систем
Любые процессы кластера серверов могут функционировать как под операционной системы Linux, так и под операционной системы Windows. Это достигается тем, что взаимодействие кластеров происходит под управлением протокола TCP/IP. Также в состав кластера могут входить рабочие серверы под управлением любой из этих операционных систем.
Утилита администрирования кластера серверов 8.3
В комплекте поставки системы имеется утилита для администрирования варианта клиент-серверной работы. Эта утилита дает возможность изменения состава кластера, управления информационными базами, и оперативно анализировать транзакционные блокировки.
После нескольких лет молчания, решил поделиться опытом по развертыванию отказоустойчивого кластера на основе Windows Server 2012.Постановка задачи: Развернуть отказоустойчивый кластер для размещения на нем виртуальных машин, с возможностью выделения виртуальных машин в отдельные виртуальные подсети (VLAN), обеспечить высокую надежность, возможность попеременного обслуживания серверов, обеспечить доступность сервисов. Обеспечить спокойный сон отделу ИТ.
Для выполнения выше поставленной задачи нам удалось выбить себе следующее оборудование:
- Сервер HP ProLiant DL 560 Gen8 4x Xeon 8 core 64 GB RAM 2 шт.
- SAS Хранилище HP P2000 на 24 2,5» дисков 1 шт.
- Диски для хранилища 300 Gb 24 шт. //С объемом не густо, но к сожалению бюджеты такие бюджеты…
- Контроллер для подключения SAS производства HP 2 шт.
- Сетевой адаптер на 4 1Gb порта 2 шт. //Можно было взять модуль под 4 SFP, но у нас нет оборудования с поддержкой 10 Gb, гигабитного соединения вполне достаточно.
Организация подключений:

У нас на самом деле подключено в 2 разных коммутатора. Можно подключить в 4 разных. Я считаю, что достаточно 2х.
На портах коммутаторов, куда подключены сервера необходимо сменить режим интерфейса с access на trunk, для возможности разнесения по виртуальным подсетям.
Пока качаются обновления на свежеустановленную Windows Server 2012, настроим дисковое хранилище. Мы планируем развернуть сервер баз данных, посему решили 600 Гб использовать под базы данных, остальное под остальные виртуальные машины, такая вот тавтология.
Создаем виртуальные диски:
- Диск raid10 на основе Raid 1+0 из 4 дисков +1 spare
- Диск raid5 на основе Raid 5 из 16 дисков +1 spare
- 2 диска - ЗИП
Теперь необходимо создать разделы.
- raid5_quorum - Так называемый диск-свидетель (witness). Необходим для организации кластера из 2 нод.
- raid5_store - Здесь мы будем хранить виртуальные машины и их жесткие диски
- raid10_db - Здесь будет хранится жесткий диск виртуальной машины MS SQL сервера
Обязательно необходимо включить feature Microsoft Multipath IO, иначе при сервера к обоим контроллерам хранилища в системе будет 6 дисков, вместо 3х, и кластер не соберется, выдавая ошибку, мол у вас присутствуют диски с одинаковыми серийными номерами, и этот визард будет прав, хочу я вам сказать.
Подключать сервера к хранилищу советую по очереди:
- Подключили 1 сервер к 1 контроллеру хранилища
- В хранилище появится 1 подключенный хост - дайте ему имя. Советую называть так: имясервера_номер контроллера (A или B)
- И так, пока не подключите оба сервера к обоим контроллерам.
На коммутаторах, к которым подключены сервера необходимо создать 3 виртуальных подсети (VLAN):
- ClusterNetwork - здесь ходит служебная информаци кластера (хэртбит, регулирование записи на хранилище)
- LiveMigration - тут думаю все ясно
- Management - сеть для управления
На этом подготовка инфраструктуры закончена. Переходим к настройке серверов и поднятию кластера.
Заводим сервера в домен. Устанавливаем роль Hyper-V, Failover Cluster.
В настройках Multipath IO включаем поддержку SAS устройств.
Обязательно перезагружаем.
Следующие настройки необходимо выполнить на обоих серверах.
Переименуйте все 4 сетевых интерфейса в соответствии их физическим портам (у нас это 1,2,3,4).
Настраиваем NIC Teaming - Добавляем все 4 адаптера в команду, Режим (Teaming-Mode) - Switch Independent, Балансировка нагрузки (Load Balancing) - Hyper-V Port. Даем имя команде, я так и назвал Team.
Теперь необходимо поднять виртуальный коммутатор.
Открываем powershell и пишем:
New-VMSwitch "VSwitch" -MinimumBandwidthMode Weight -NetAdapterName "Team" -AllowManagementOS 0
Создаем 3 виртуальных сетевых адаптера.
В том же powershell:
Add-VMNetworkAdapter –ManagementOS –Name "Management" Add-VMNetworkAdapter –ManagementOS –Name "ClusterNetwork"Add-VMNetworkAdapter –ManagementOS –Name "Live Migration"
Эти виртуальные коммутаторы появятся в центре управления сетями и общим доступом, именно по ним и будет ходить траффик наших серверов.
Настройте адресацию в соответствии с вашими планами.
Переводим наши адапетры в соответствующие VLAN’ы.
В любимом powershell:
Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 2 -VMNetworkAdapterName "Management" -Confirm Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 3 -VMNetworkAdapterName "ClusterNetwork" -Confirm Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 4 -VMNetworkAdapterName "Live Migration" -Confirm
Теперь нужно настроить QoS.
При настройке QoS by weight (по весу), что является best practice, по заявлению Microsoft, советую расставить вес так, чтобы в общей сумме получилось 100, тогда можно считать, что значение указанное в настройке есть гарантированный процент полосы пропускания. В любом случае считается процент по формуле:
Процент полосы пропускания = установленный вес * 100 / сумма всех установленных значений веса
Set-VMSwitch “VSwitch” -DefaultFlowMinimumBandwidthWeight 15
Для служебной информации кластера.
Set-VMNetworkAdapter -ManagementOS -Name “Cluster” -MinimumBandwidthWeight 30
Для управления.
Set-VMNetworkAdapter -ManagementOS -Name "Management" -MinimumBandwidthWeight 5
Для Live Migration.
Set-VMNetworkAdapter -ManagementOS -Name “Live Migration” -MinimumBandwidthWeight 50
Чтобы трафик ходил по сетям верно, необходимо верно расставить метрики.
Трафик служебной информации кластера будет ходит по сети с наименьшей метрикой.По следующей по величине метрики сети будет ходить Live Migration.
Давайте так и сделаем.
В нашем ненаглядном:
$n = Get-ClusterNetwork “ClusterNetwork” $n.Metric = 1000 $n = Get-ClusterNetwork “LiveMigration” $n.Metric = 1050$n = Get-ClusterNetwork “Management” $n.Metric = 1100
Монтируем наш диск-свидетель на ноде, с которой будем собирать кластер, форматируем в ntfs.
В оснастке Failover Clustering в разделе Networks переименуйте сети в соответствии с нашими адаптерами.
Все готово к сбору кластера.
В оснастке Failover Clustering жмем validate. Проходим проверку. После чего создаем кластер (create cluster) и выбираем конфигурацию кворума (quorum configuration) Node and Disk majority, что также считается лучшим выбором для кластеров с четным количеством нод, а учитывая, что у нас их всего две - это единственный выбор.
В разделе Storage оснастки Failover Clustering, добавьте ваши диски. А затем по очереди добавляйте их как Cluster Shared Volume (правый клик по диску). После добавления в папке C:\ClusterStorage появится символическая ссылка на диск, переименуйте ее в соответствии с названием диска, добавленного как Cluster Shared Volume.
Теперь можно создавать виртуальные машины и сохранять их на эти разделы. Надеюсь статья была Вам полезна.
Прошу сообщать об ошибках в ПМ.
Советую к прочтению: Microsoft Windows Server 2012 Полное руководство. Рэнд Моримото, Майкл Ноэл, Гай Ярдени, Омар Драуби, Эндрю Аббейт, Крис Амарис.
P.S.: Отдельное спасибо господину Салахову, Загорскому и Разборнову, которые постыдно были забыты мною при написании данного поста. Каюсь >_< XD
MTBF (Mean Time Between Failure) — среднее время наработки на отказ.
MTTR (Mean Time To Repair) — среднее время восстановления работоспособности.
В отличие от надежности, величина которой определяется только значением MTBF, готовность зависит еще и от времени, необходимого для возврата системы в рабочее состояние.
Что такое кластер высокой готовности?
Кластер высокой готовности (далее кластер) — это разновидность кластерной системы, предназначенная для обеспечения непрерывной работы критически важных приложений или служб. Применение кластера высокой готовности позволяет предотвратить как неплановые простои, вызываемые отказами аппаратуры и программного обеспечения, так и плановые простои, необходимые для обновления программного обеспечения или профилактического ремонта оборудования.
Принципиальная схема кластера высокой готовности приведена на рисунке:
Кластер состоит из двух узлов (серверов), подключенных к общему дисковому массиву. Все основные компоненты этого дискового массива — блок питания, дисковые накопители, контроллер ввода/вывода - имеют резервирование с возможностью горячей замены. Узлы кластера соединены между собой внутренней сетью для обмена информацией о своем текущем состоянии. Электропитание кластера осуществляется от двух независимых источников. Подключение каждого узла к внешней локальной сети также дублируется.
Таким образом, все подсистемы кластера имеют резервирование, поэтому при отказе любого элемента кластер в целом останется в работоспособном состоянии. Более того, замена отказавшего элемента возможна без остановки кластера.
На обоих узлах кластера устанавливается операционная система Microsoft Windows Server 2003 Enterprise, которая поддерживает технологию Microsoft Windows Cluster Service (MSCS).
Принцип работы кластера следующий. Приложение (служба), доступность которого обеспечивается кластером, устанавливается на обоих узлах. Для этого приложения (службы) создается группа ресурсов, включающая IP-адрес и сетевое имя виртуального сервера, а также один или несколько логических дисков на общем дисковом массиве. Таким образом, приложение вместе со своей группой ресурсов не привязывается "жестко" к конретному узлу, а, напротив, может быть запущено на любом из этих узлов (причем на каждом узле одновременно может работать несколько приложений). В свою очередь, клиенты этого приложения (службы) будут "видеть" в сети не узлы кластера, а виртуальный сервер (сетевое имя и IP-адрес), на котором работает данное приложение.
Сначала приложение запускается на одном из узлов. Если этот узел по какой-либо причине прекращает функционировать, другой узел перестает получать от него сигнал активности ("heartbeat") и автоматически запускает все приложения отказавшего узла, т.е. приложения вместе со своими группами ресурсов "мигрируют" на исправный узел. Миграция приложения может продолжаться от нескольких секунд до нескольких десятков секунд и в течение этого времени данное приложение недоступно для клиентов. В зависимости от типа приложения после рестарта сеанс возобновляется автоматически либо может потребоваться повторная авторизация клиента. Никаких изменений настроек со стороны клиента не нужно. После восстановления неисправного узла его приложения могут мигрировать обратно.
Если на каждом узле кластера работают различные приложения, то в случае отказа одного из узлов нагрузка на другой узел повысится и производительность приложений упадет.
Если приложения работают только на одном узле, а другой узел используется в качестве резерва, то при отказе "рабочего" узла производительность кластера не изменится (при условии, что запасной узел не "слабее").
Основным преимуществом кластеров высокой готовности является возможность использования стандартного оборудования и программного обеспечения, что делает это решение недорогим и доступным для внедрения предприятиями малого и среднего бизнеса.
Следует отличать кластеры высокой готовности от отказоустойчивых систем ("fault-tolerant"), которые строятся по принципу полного дублирования. В таких системах серверы работают параллельно в синхронном режиме. Достоинством этих систем является малое (меньше секунды) время восстановления после отказа, а недостатком - высокая стоимость из-за необходимости применения специальных программных и аппаратных решений.
Сравнение кластера высокой готовности с обычным сервером
Как упоминалось выше, применение кластеров высокой готовности позволяет уменьшить число простоев, вызванное плановыми или неплановыми остановками работы.
Плановые остановки могут быть обусловлены необходимостью обновления программного обеспечения или проведения профилактического ремонта оборудования. На кластере эти операции можно проводить последовательно на разных узлах, не прерывая работы кластера в целом.
Неплановые остановки случаются из-за сбоев программного обеспечения или аппаратуры. В случае сбоя ПО на обычном сервере потребуется перезагрузка операционной системы или приложения, в случае с кластером приложение мигрирует на другой узел и продолжит работу.
Наименее предсказуемым событием является отказ оборудования. Из опыта известно, что сервер является достаточно надежным устройством. Но можно ли получить конкретные цифры, отражающие уровень готовности сервера и кластера?
Производители компьютерных компонентов, как правило, определяют их надежность на основании испытаний партии изделий по следующей формуле:
Например, если тестировалось 100 изделий в течение года и 10 из них вышло из строя, то MTBF, вычисленное по этой формуле, будет равно 10 годам. Т.е. предполагается, что через 10 лет все изделия выйдут из строя.
Отсюда можно сделать следующие важные выводы. Во-первых, такая методика расчета MTBF предполагает, что число отказов в единицу времени постоянно на протяжении всего срока эксплуатации. В "реальной" жизни это, конечно, не так. На самом деле, из теории надежности известно, что кривая отказов имеет следующий вид:

В зоне I проявляются отказы изделий, имеющие дефекты изготовления. В III зоне начинают сказываться усталостные изменения. В зоне II отказы вызываются случайными факторами и их число постоянно в единицу времени. Изготовители компонентов, "распространяют" эту зону на весь срок эксплуатации. Реальная статистика отказов на протяжение всего срока эксплуатации подтверждает, что эта теоретическая модель вполне близка к действительности.
Второй интересный вывод заключается в том, что понятие MTBF отражает совсем не то, что очевидно следует из его названия. "Среднее время наработки на отказ" в буквальном смысле означает время, составляющее только половину MTBF. Так, в нашем примере это "среднее время" будет не 10 лет, а пять, поскольку в среднем все экземпляры изделия проработают не 10 лет, а вполовину меньше. Т.е. MTBF, заявляемый производителем - это время, в течение которого изделие выйдет из строя с вероятностью 100%.
Итак, поскольку вероятность выхода компонента из строя на протяжении MTBF равна 1, и если MTBF измерять в годах, то вероятность выхода компонента из строя в течение одного года составит:
| P = | 1 |
| MTBF |
Очевидно, что отказ любого из недублированных компонентов сервера будет означать отказ сервера в целом.
Отказ дублированного компонента приведет к отказу сервера только при условии, что компонент-дублер тоже выйдет из строя в течение времени, необходимого для "горячей" замены компонента, отказавшего первым. Если гарантированное время замены компонента составляет 24 часа (1/365 года) (что соответствует сложившейся практике обслуживания серверного оборудования), то вероятность такого события в течение года:
| Pd = | P x P | x 2 |
| 365 |
Пояснения к формуле.
Здесь мы имеем два взаимоисключающих случая, когда оба компонента выходят из строя.
Случай (1)
- Выход из строя компонента №1 в любой момент времени в течение года (вероятность P)
- Выход из строя компонента №2 в течение 24 часов после выхода компонента №1 (вероятность P/365)
Вероятность одновременного наступления этих событий равняется произведению их вероятностей.
Для случая (2), когда сначала откажет компонент №2, а затем компонент №1, вероятность будет такой же.
Поскольку случаи (1) и (2) не могут произойти одновременно, вероятность наступления того или другого случая равна сумме их вероятностей.
Теперь, зная вероятность Pi отказа каждого из N компонентов (дублированных и недублированных) сервера, можно рассчитать вероятность отказа сервера в течение одного года.
Выполним расчет следующим образом.
Как уже говорилось выход их строя любого компонента будет означать отказ сервера в целом.
Вероятность безотказной работы любого компонента в течение года равна
| Pi" = 1 - Pi |
Вероятность безотказной работы всех компонентов в течение года равна произведению вероятностей этих независимых событий:
| Ps’ = ∏ Pi" |
Тогда вероятность выхода сервера из строя в течение года
Теперь можно определить коэффициент готовности:
| Ks = | MTBFs |
| MTBFs + MTTRs |
Перейдем к расчету. Пусть наш сервер состоит из следующих компонентов:

Рисунок 1. Состав сервера
Сведем данные производителей по надежности отдельных компонент, в следующую таблицу:
| Компоненты сервера | Заявленная надежность | Количество компонентов в сервере | Вероятность отказа с учетом дублирования |
||
| MTBF (часов) | MTBF (лет) | Вероятность отказа в те- чение года |
|||
| Блок питания | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| Системная плата | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Процессор №1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Процессор №2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, модуль №1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, модуль №2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Жесткий диск | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Вентилятор №1 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Вентилятор №2 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Контроллер HDD | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Плата сопряжения | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Ленточный накопитель | 220 000 | 25,11 | 0,03982 | 1 | 0,0398182 |
| Для сервера в целом: | 0,37664 | 0,1519961 | |||
Вообще, для серверного оборудования нормальным коэффициентом готовности считается величина 99,95%, что примерно соответствует результату наших расчетов.
Выполним аналогичный расчет для кластера.
Кластер состоит из двух узлов и внешнего дискового массива. Нарушение работоспособности кластера произойдет либо в случае отказа дискового массива либо в случае одновременного отказа обеих узлов в течение времени, необходимого для восстановления узла, первым вышедшего из строя.
Предположим, что в качестве узла кластера используется рассмотренный нами сервер с коэффициентом готовности K = 99,958%, а время восстановления работоспособности узла - 24 часа.
Рассчитаем параметры надежности внешнего дискового массива:
| Компоненты массива | Заявленная надежность | Кол-во компо- нентов в массиве | Вероятность отказа с учетом дублирования |
||
| MTBF (часов) | MTBF (лет) | Вероятность отказа в те- чение года |
|||
| Блок питания | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| Жесткий диск | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Вентилятор | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Контроллер HDD | 300 000 | 34,25 | 0,02920 | 2 | 0,0000047 |
| Для массива в целом: | 0,21797 | 0,0001013 | |||
Таким образом, кластер высокой готовности демонстрирует гораздо более высокую устройчивость к возможному отказу аппаратуры, нежели сервер традиционной архитектуры.
Может не справиться с нагрузкой, зависнуть или быть выключенным ради профилактики. Поэтому для обеспечения повышенного уровня надёжности придумана такая полезная штука как кластер серверов. Ну а раз уж данное явление существует, то с ним надо познакомиться, чем и займёмся.
Суть вкратце
Кластер серверов - это не просто несколько компьютеров, соединённых друг с другом проводами, «витыми парами». Это, в первую очередь, программное обеспечение , которое управляет всем этим «железом», распределяет запросы, синхронизирует, осуществляет балансировку нагрузки, подключает базу данных... Впрочем, лучше растолковывать суть явления на конкретном примере.
Пример схемы кластера серверов
В качестве примера возьмём весьма популярный софт «1С:Предприятие 8». Упрощённая схема функционирования кластера серверов выглядит примерно следующим образом.
Клиентское приложение (в смысле, приложение на компьютере пользователя) осуществляет запрос по протоколу TCP/IP. Этот запрос приходит на центральный сервер в кластере, где действует программа-менеджер (Cluster Manager) и располагается реестр кластера.
Центральный сервер на лету анализирует обстановку с загруженностью и перенаправляет запрос (тоже по TCP/IP) на тот компьютер в кластере, у которого в этот момент есть возможность наиболее быстро и эффективно обработать обращение пользователя. После чего за обслуживание запроса берётся конкретный рабочий процесс на конкретной машине.
Рабочий процесс начинает взаимодействовать с клиентским приложением напрямую. Плюс подключается к отдельному серверу с базой данных, который скромно стоит в сторонке, но при этом обслуживает весь кластер. То есть, после успешного срабатывания схемы получается цепочка с двусторонним движением между компонентами: клиентское приложение - рабочий процесс в кластере - сервер базы данных.
Как видим, центральный сервер кластера и его программа-менеджер участия уже не принимают, они своё дело сделали.
Microsoft
Для организации кластера серверов на основе софта от корпорации Microsoft требуется операционная система «Microsoft® Windows Server™ 2008», причём, «Enterprise Edition» или «Datacenter Edition». Там есть софт «Windows Server Failover Clustering». (Ранее, в релизе ОС за 2003-й год, программное изделие называлось «Microsoft Cluster Server», сокращённо MSCS.)
По версии Microsoft, кластер - это несколько узлов (то бишь, компьютеров) общим количеством до шестнадцати штук (в релизе 2003-го - до восьми), объединённых в единую систему. Один узел впал в ступор сам или был выключен для технического обслуживания - его функции сразу же передаются другому.
Кластер в Windows Server создаётся с помощью графического интерфейса «Cluster Control Panel». Десяток диалоговых окошек - и готово.
Oracle
Компания Oracle для создания кластеров производит продукт «WebLogic». Есть версии и для Windows , и для GNU/Linux .
Велосипед изобретать не стали: работой и балансировкой нагрузки руководит сервер-администратор (Admin Server), к которому подключены узлы (Managed Servers). Всё вместе объединяется в единый домен.
Причём, с помощью «WebLogic» в домен можно сгруппировать даже не один, а несколько кластеров. Кроме того, доступны: 1) репликация пользовательских сессий в серверах кластера; 2) балансировка нагрузки (с помощью компонента HttpClusterServlet).
Настройка посложнее, диалоговых окошек много. Но зато можно либо создать кластер самостоятельно с нуля, либо использовать готовый шаблон.
Кроме того, имеется продукт «Oracle Real Application Clusters» (сокращённо «Oracle RAC») для синхронизированной работы «Oracle Database» на нескольких узлах, что тоже по своей сути является кластером.
Заключение
Благодаря умному софту кластер выглядит «со стороны», с точки зрения клиента, как один единственный компьютер, к которому осуществляется запрос. В этом отличие кластера от Grid-систем распределённых вычислений, где компьютеры вовсе необязательно объединены в домен, вполне могут быть удалёнными.
Кластер серверов очень уместен и полезен для систем, подверженных нешуточным рабочим нагрузкам. И если предприятие расширяется, клиенты множатся и потихоньку начинают ворчать из-за торможения сервиса, то имеет смысл задуматься над внедрением вышеописанной технологии.
Предыдущие публикации:
|
Быстрое внедрение ERP
Комплексные услуги |
Управление доставкой Для торговых и курьерских компаний! |
1C:ЭДО Узнайте о всех преимуществах электронного документооборота! |
Переход на «1С:ЗУП ред. 3» Фирма «1С» прекращает поддержку «1С:ЗУП 2.5»! |
Аренда сервера 1С |



Кластер серверов 1С - построение высоконагруженных систем
Заказать демонстрацию ЗаказатьВ данной статье будут рассмотрены несколько вариантов структуры 1С для высоконагруженных систем (от 200 активных пользователей), построенных на базе клиент-серверной архитектуры – их преимущества и недостатки, стоимость инсталляции и сравнительные тесты производительности каждого варианта.
Мы не будем проводить описание, оценку и сравнение общепринятых и всем давно известных классических схем построения серверной структуры 1С, таких как отдельный сервер 1С и отдельный сервер СУБД, либо кластер Microsoft SQL с кластером 1С. Таких обзоров великое множество, в том числе и проведенных самими производителями программных продуктов. Мы предложим обзор схем построения структуры 1С, которые встречались за последние несколько лет в наших ИТ-проектах для среднего и крупного бизнеса.
Требования к высоконагруженным системам 1С
Высоконагруженные системы 1С, работающие с крупными массивами данных в режиме 24/7/365 подвержены факторам риска, которые в стандартных ситуациях обычно не наблюдаются. Как следствие, для их устранения и упреждения требуется применение особенных схем архитектуры 1С и новых технологий.
Катастрофоустойчивость СУБД. В процессе проектирования архитектуры 1С делается упор на вычислительные мощности и высокую доступность сервисов, выраженную в их кластеризации. Серверы 1С:Предприятие по умолчанию способны работать в дублирующем кластере, а для кластера СУБД обычно применяется промышленная система хранения данных (СХД) и технология кластеризации (к примеру, Microsoft SQL Cluster). Однако, ситуация становится плачевной, когда проблемы случаются с самой СХД (зачастую, по нашему опыту последних лет – это проблемы программного характера). Тогда у ИТ-инженера резко возникают две проблемы – где взять актуальные данные и куда их развернуть в кратчайшие сроки, поскольку система хранения данных с нужным объемом быстрого массива дисков недоступна.
Требования к безопасности базы данных. Работая с проектами среднего и крупного бизнеса, мы регулярно сталкиваемся с требованиями по защите персональных данных (в частности, для выполнения пунктов ФЗ-152). Одним из условий выполнения этих требований является обеспечение должной сохранности персональных данных, что требует шифрования базы данных 1С.
При разработке схемы высоконагруженных систем 1С обычно обращают внимание в первую очередь на параметры дисковой системы ввода\вывода, на которой расположены базы данных. Но помимо этого, еще существует активная утилизация ресурсов ЦПУ и потребление ОЗУ сервером 1С. Зачастую именно этого типа ресурсов и не хватает, возможности аппаратной модернизации текущего сервера 1С исчерпываются и требуется добавление новых серверов 1С, работающих с единым сервером СУБД.Схемы организации кластеров серверов 1С
Схема с кластером 1С-серверов, подсоединенным к кластеру с синхронной репликацией SQL AlwaysOn по протоколу IP. Данная схема является одним из качественных вариантов решения проблемы катастрофоустойчивости базы данных 1С (см. Рисунок 1). Технология кластеризации баз SQL AlwaysOn основана на принципе онлайн-синхронизации таблиц SQL между основным и резервным серверами без вмешательства конечного пользователя. С помощью SQL Listener есть возможность переключиться на резервный сервер SQL в случае выхода из строя основного, что позволяет назвать данную систему полноценным катастрофоустойчивым кластером SQL, благодаря использованию двух независимых серверов SQL. Технология SQL Always On доступна только в версии Microsoft SQL Enterprise.

Рисунок 1 - схема кластера серверов 1С + SQL AlwaysOn
Вторая схема идентична первой, добавлено только шифрование баз SQL на основном и резервном сервере. Мы уже упоминали о том, что работа с последними ИТ-проектами показала, что компании начали гораздо больше внимания уделять вопросу безопасности данных, по различным причинам – требования ФЗ-152, рейдерские захваты серверов, утечка данных в облаке и тому подобное. Так что считаем данный вариант схемы 1С довольно актуальным (см. Рисунок 2).

Рисунок 2 - схема кластера серверов 1С + SQL AlwaysOn с шифрованием
Кластер серверов 1С "active-active", подсоединенный к единственному серверу СУБД по протоколу IP. В противовес потребностям в отказоустойчивости и безопасности – некоторым структурам в первую очередь требуется повышенная производительность, так сказать «вся вычислительная мощь». Поэтому максимальный приоритет отдается увеличению количества вычислительных кластеров сервера 1С, на которые современная платформа 1С позволяет дифференцировать различные типы вычислений и фоновые задания (см. Рисунок 3). Конечно же, комплектация основных ресурсов сервера SQL тоже должна быть на уровне, однако сам сервер баз данных представлен в единственном числе (видимо, расчет идет на своевременное резервное копирование баз).
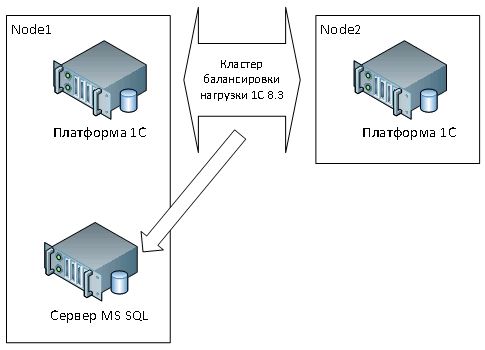
Рисунок 3 - схема кластера серверов 1С с одним сервером СУБД
Сервер 1С и СУБД на одном аппаратном сервере с SharedMemory. Поскольку наши практические тесты ориентированы на сравнение производительности разных схем, то обязательно требуется некий эталон для сравнения нескольких вариантов (см. Рисунок 4). В качестве эталона, по нашему мнению, нужно взять схему расположения сервера 1С и СУБД на одном аппаратном сервере без виртуализации с взаимодействием по SharedMemory.

Рисунок 4 - схема сервера 1С и СУБД на одном аппаратном сервере с SharedMemory
Ниже приведена общая сравнительная таблица, в которой показаны общие результаты по ключевым критериям оценки организации структуры системы 1С (см. Таблица 1).
| Критерии оценки архитектур 1С | Кластер 1С + SQL AlwaysOn |
Кластер 1С + SQL AlwaysOn с шифрованием
|
Кластер 1С с одним сервером СУБД
|
Классический 1С+СУБД SharedMemory |
| Легкость инсталляции и обслуживания | Удовл. | Удовл. | Хорошо | Отлично |
| Отказоустойчивость | Отлично | Отлично | Удовл. | Не применимо |
| Безопасность | Удовл. | Отлично | Удовл. | Удовл. |
| Бюджетность | Удовл. | Удовл. | Хорошо | Отлично |
Таблица 1 - сравнение вариантов построения систем 1С
Как видим, остается один важный критерий, значение которого предстоит выяснить – это производительность. Для этого мы проведем серию практических тестов на выделенном тестовом стенде.
Описание методики тестирования
Этап тестирования состоит из двух ключевых инструментов синтетической генерации нагрузки и имитации работы пользователей в 1С. Это тест Гилева (TPC-1C) и «Тест центр» из инструментария 1С: КИП.
Тест Гилева. Тест относится к разделу универсальных интегральных кроссплатформенных тестов. Он может применяться как для файлового, так и для клиент-серверного вариантов 1С:Предприятие. Тест оценивает количество работы в единицу времени в одном потоке и подходит для оценки скорости работы однопоточных нагрузок, включая скорость отрисовки интерфейса, влияния ресурсных затрат на обслуживание виртуальной среды, перепроведения документов, закрытия месяца, расчета зарплаты и т.п. Универсальность позволяет делать обобщенную оценку производительности не привязываясь к конкретной типовой конфигурации платформы. Результатом теста является сводная оценка измеряемой системы 1С, выраженная в условных единицах.
Специализированный «Тест центр» из инструментария 1С: КИП. Тест-центр – инструмент автоматизации многопользовательских нагрузочных испытаний информационных систем на платформе 1С:Предприятие 8. С его помощью можно моделировать работу предприятия без участия реальных пользователей, что позволяет оценивать применимость, производительность и масштабируемость информационной системы в реальных условиях. Используя инструментарий 1С: КИП, на основании процессов и контрольных примеров формируется матрица «Список Объектов макета базы ERP 2.2» для сценария тестирования производительности. В макете базы 1С: ERP 2.2 генерируются обработкой данные по Нормативно-справочной информации (НСИ):
- Несколько тысяч номенклатурных позиций;
- Несколько организаций;
- Несколько тысяч контрагентов.
Тест осуществляется в рамках нескольких групп пользователей. Группа состоит из 4 пользователей, у каждого из которых есть своя роль и перечень последовательных операций. Благодаря гибкому механизму задания параметров для тестирования, можно запускать тест на разное количество пользователей, что позволит оценить поведение системы при различных нагрузках и определить параметры, которые могут привести к снижению показателей производительности. Проводится 3 теста по 3 итерации в которых разработчик 1С запускает тест с эмуляцией работы пользователей и замеряет время выполнения каждой операции. Выполняются замеры всех трех итераций для каждой из схем структуры 1С. Результатом теста является получение среднего времени выполнения операции для каждого документа матрицы.
Показатели «Тест центра» и теста Гилева будут отражены в сводной таблице 2.
Тестовый стенд
Сервер терминального доступа – виртуальная машина, использовалась для управления инструментами тестирования:
- vCPU - 16 ядер 2.6GHz
- RAM - 32 ГБ
- I\o: Intel Sata SSD Raid1
- RAM - 96 ГБ
- I\o: Intel Sata SSD Raid1
Сервер 1С и СУБД - физический сервер
- CPU - Intel Xeon Processor E5-2670 8C 2.6GHz – 2 шт
- RAM - 96 ГБ
- I\o: Intel Sata SSD Raid1
- Роли: Сервер 1С 8.3.8.2137, Сервер MS SQL 2014 SP 2
Выводы
Можем сделать вывод, что по среднему времени выполнения операции наиболее оптимальной является схема №3 «Кластер серверов 1С "active-active", подсоединенный к единственному серверу СУБД по протоколу IP» (см. Таблица 2). Для обеспечения отказоустойчивости такой архитектуры мы рекомендуем строить классический отказоустойчивый кластер MSSQL с размещением базы данных на отдельной СХД.
Важно отметить, что наиболее оптимальное соотношение факторов минимизации простоя, отказоустойчивости и сохранности данных - у схемы №1 «Кластер 1С-серверов, подсоединенный к кластеру с синхронной репликацией SQL AlwaysOn по протоколу IP», при этом падение производительности по отношению к самому производительному варианту составляет примерно 10%.
Как мы видим по результатам тестов, синхронная репликация базы SQL AlwaysOn достаточно негативно влияет на производительность. Объясняется это тем, что система SQL ждет окончания репликации каждой транзакции на резервный сервер, не позволяя работать с базой в это время. Этого можно избежать если настроить асинхронную репликацию между MSSQL серверами, но при таких настройках мы не получим автоматического переключения приложений на резервную ноду в случае сбоя. Переключение придется выполнять вручную.
На базе облака EFSOL мы предлагаем нашим клиентам кластер серверов 1С в аренду. Это позволяет существенно сэкономить средства на построение собственной отказоустойчивой архитектуры для работы с 1С.
|
Схема архитектуры 1С |
Среднее время выполнения операции, сек | ||