Типы и характеристики процессоров. Процессоры Intel - как устроены и основные принципы. Увеличенный объем кэш памят
В таблице кратко охарактеризованы основные ранние этапы развития процессоров Intel и их аналогов. Здесь же мы далее перейдем к рассмотрению процессоров Pentium.
Pentium - пятое поколение МП 22 марта 1993 года
Pentium представляет собой суперскалярный процессор с 32-битовой адресной шиной и 64-битовой шиной данных, изготовленный по субмикронной технологии с комплиментарной МОП структурой и состоящий из 3.1 миллионов транзисторов (на площади в 16.25 квадратных сантиметров). Процессор включает следующие блоки.
Энергопотребление и тепловыделение
Тем не менее, атом доминирует над гиперпотоком, чтобы более эффективно использовать единицы команды. Оба процессора теперь предлагают турбо-ядерную функцию. Во-первых, знать, что такое микропроцессор? Микропроцессор - это элемент компьютера, который отвечает за выполнение логических операций и арифметических операций. Он также отвечает за управление трафиком через материнскую плату и управление компьютером.
Скорость микрофона выражается в Гц, что является числом операций, которые могут быть выполнены за секунду. Процессор, несомненно, является самым дорогим компонентом системы, стоимость которого в четыре или более раз больше, чем у материнской платы. Ядра в микропроцессорах.
Таблица с характеристиками процессоров Intel, Cyrix, AMD
| Тип процессора | Поколение | Год выпуска | Разрядность шины данных | Разрядность | Первичная кэш память, Кбайт | |
|---|---|---|---|---|---|---|
| Команды | Данные | |||||
| 8088 | 1 | 1979 | 8 | 20 | Нет | |
| 8086 | 1 | 1978 | 16 | 20 | Нет | |
| 80286 | 2 | 1982 | 16 | 24 | Нет | |
| 80386DX | 3 | 1985 | 32 | 32 | Нет | |
| 80386SX | 3 | 1988 | 16 | 32 | 8 | |
| 80486DX | 4 | 1989 | 32 | 32 | 8 | |
| 80486SX | 4 | 1989 | 32 | 32 | 8 | |
| 80486DX2 | 4 | 1992 | 32 | 32 | 8 | |
| 80486DX4 | 5 | 1994 | 32 | 32 | 8 | 8 |
| Pentium | 5 | 1993 | 64 | 32 | 8 | 8 |
| Р-ММХ | 5 | 1997 | 64 | 32 | 16 | 16 |
| Pentium Pro | 6 | 1995 | 64 | 32 | 8 | 8 |
| Pentium ll | 6 | 1997 | 64 | 32 | 16 | 16 |
| Pentium ll Celeron | 6 | 1998 | 64 | 32 | 16 | 16 |
| Pentium Xeon | 6-7 | 1998 | ||||
| Pentium lll | 6 | 1999 | 64 | 32 | 16 | 16 |
| Pentium lV | 7 | 2000 | 64 | 32 | 12 | 8 |
| 6 | 1997-1998 | 16-32-64 | 16-32-64 | 16-64 | ||
| AMD K6, K6-2 | 6 | 1997-1999 | 16-64 | 16-64 | 32 | 32 |
| AMD K6-3 | ||||||
| AMD Athlon | 7 | 1999 | 64 | 32 | 64 | 64 |
| AMD Athlon 64 | 8 | 2003 | 64 | 64 | 64 | 64 |
| Тип процессора | Тактовая частота шины, МГц | |||
|---|---|---|---|---|
| 8088 | 4.77-8 | 4.77-8 | ||
| 8086 | 4.77-8 | 4.77-8 | 0.029 | 3.0 |
| 80286 | 6-20 | 6-20 | 0.130 | 1.5 |
| 80386DX | 16-33 | 16-33 | 0.27 | 1.0 |
| 80386SX | 16-33 | 16-33 | 0.27 | 1.0 |
| 80486DX | 25-50 | 25-50 | 1.2 | 1.0-0.8 |
| 80486SX | 25-50 | 25-50 | 1.1 | 0.8 |
| 80486DX2 | 25-40 | 50-80 | ||
| 80486DX4 | 25-40 | 75-120 | ||
| Pentium | 60-66 | 60-200 | 3.1-3.3 | 0.8-0.35 |
| Р-ММХ | 66 | 166-233 | 4.5 | 0.6-0.35 |
| Pentium Pro | 66 | 150-200 | 5.5 | 0.35 |
| Pentium ll | 66 | 233-300 | 7.5 | 0.35-0.25 |
| Pentium ll Celeron | 66/100 | 266-533 | 7.5-19 | 0.25 |
| Pentium Xeon | 100 | 400-1700 | 0.18 | |
| Pentium lll | 106 | 450-1200 | 9.5-44 | 0.25-0.13 |
| Pentium lV | 400 | 1.4-3.4 ГГц | 42-125 | 0.18-0.09 |
| Cyrix 6 x 86, Media GX, MX, Mll | 75 | 187-233-300-333 | 3.5 | 0.35-0.25-0.22-0.18 |
| AMD K6, K6-2 | 100 | 166-233- | 8.8 | 0.35-0.25 |
| AMD K6 3 | 450-550 | |||
| AMD Athlon | 266 | 500-2200 | 22 | 0.25 |
| AMD Athlon 64 | 400 | 2 ГГц | 54-106 | 0.13-0.09 |
Таблица с характеристиками процессоров Intel
| Тип процессора | Архитектура | Год выпуска | Кодовое наименование | Количество транзисторов, в миллионах | Ядро, мм | L1-кэш, Кбайт | L2-кэш, Кбайт |
|---|---|---|---|---|---|---|---|
| Pentium | P5 | 1993 | Р5 | 3.1 | 294 | 2 x 8 | Внешн. |
| 1994-1995 | Р54 | 3.3 | 148 | 16 | Внешн. | ||
| 1995-1996 | Р54С | 3.3 | 83-91 | 16 | Внешн. | ||
| ММХ | 1996-1997 | Р55С | 4.5 | 140-128 | 2 x 16 | Внешн. | |
| PRO | P6 | 1995-1997 | Р6 | 5.5 | 306-195 | 2 x 8 | 256-1 Мбайт |
| Pentium 2 | 1997 | Klamath | 7.5 | 203 | 2 x 16 | 512 | |
| 1998 | Deschutes | 7.5 | 131-118 | 2 x 16 | 512 | ||
| Pentium 2 | 1999 | Katmai | 9.5 | 123 | 32 | 512 | |
| 1999-2000 | Coppermine | 28.1 | 106-90 | 32 | 256 | ||
| 2001-2002 | Tualatin | 44.0 | 95-80 | 32 | 256 | ||
| Pentium IV | Netburst (IA-32e) | 2000-2001 | Willamette | 42.0 | 217 | 8+12 | 256 |
| 2002-2004 | Northwood | 55.0 | 146-131 | 8+12 | 512 | ||
| 2004-2005 | Prescott | 125.0 | 122 | 16+12 | 1024 | ||
| 2005 | Prescott 2M | 169 | 135 | 12+16 | 2048 | ||
| 2005-2006 | Cedar Mill | 188.0 | 81 | 12+16 | 2048 | ||
| Pentium D | Intel Core | 2005 | Smithfield (2xPrescott) | 230.0 | 206 | 12+6 x 2 | 2 x 1.0 Мбайт |
| 2006 | Presler (2xCedar Mill) | 376.0 | 162 | 800 | 2 x 2.0 Мбайт | ||
| Core 2 Duo | Intel Core | 2006 | Alendale | 167 | 111 | 32 x 2 | 2-4 Мбайт |
| Core 2 Extreme | 2006 | Conroe | 291 | 143 | 32 x 2 | 4 Мбайт | |
| Xeon | P5, P6, Netburst | 1998 | Ядро Pentium 2 | Смотрите Pentium 2 | 512-1.0 Мбайт | ||
| 1999-2000 | Tanner | Смотрите Pentium 3 | 512-2.0 Мбайт | ||||
| 2001 | Foster | Смотрите Pentium 4 | 512-1.0 Мбайт | ||||
| Celeron | P5, P6, Netburst | 1998 | Covington | 7.5 | 131 | 32 | Нет |
| 1998-2000 | Mendocino | 19.0 | 154 | 32 | 128 | ||
| 2000 | Coppermine | 28.1 | 105/90 | 32 | 128 | ||
| 2002 | Tualatin | 44.0 | 80 | 32 | 256 | ||
| 2002 | Willamette | 42.0 | 217 | 8 | 128 | ||
| 2002-2004 | Nordwood | 55.0 | 131 | 8 | 128 | ||
| Celeron D | Netburst | 2004-2006 | Prescott | 140.0 | 120 | 16 | 256 |
| 2004/2006 | Cedar Mill | 188.0 | 81 | 16 | 512 | ||
| Itanium | IA-64 | 1999 | Merced/Itanic | 30.0-220 | 2-4 Мбайт L3 | ||
| Itanium 2 | 2003 | Madison | 410.0 | 6.0 Мбайт L3 | |||
| Itanium (двухъядерный) | 2006 | Montecito | 1720.0 | 596 | 16+16 Кбайт L1 1 Мбайт+256 Кбайт L2 24 Мбайт L3 | ||
| Тип процессора | Размер минимальной структуры, мкм | Тактовая частота шины, МГц | Тактовая частота процессора, МГц | Потребляемая мощность, Вт | Интерфейс |
|---|---|---|---|---|---|
| Pentium | 0.8 | 60-66 | 60-66 | 14-16 | Socket 4 |
| 0.6 | 50-66 | 75-120 | 8-12 | Socket 5.7 | |
| 0.35 | 66 | 133-200 | 11-15 | Socket 7 | |
| ММХ | 0.28 | 66 | 166-233 | 13-17 | Socket 7 |
| PRO | 0.60-0.35 | 60-66 | 150-200 | 37.9 | Socket 8 |
| Pentium 2 | 0.35 | 66 | 233-300 | 34-43 | Slot1 |
| 0.25 | 66-100 | 266-450 | 18-27 | Slot 1 | |
| Pentium 3 | 0.25 | 100-133 | 450-600 | 28-34 | Slot 1 |
| 0.18 | 100 | 650-1.33 ГГц | 14-37 | Slot 1/Socket 370 | |
| 0.13 | 133 | 1.0-1.4 ГГц | 27-32 | S 370 | |
| Pentium IV | 0.18 | 400 | 1.3-2.0 ГГц | 48-66 | Socket 423/478 |
| 0.13 Си | 400-800 | 1.6-3.4 ГГц | 38-109 | Socket 478 | |
| 0.09 | 533-800 | 2.66-3.8 ГГц | 89-115 | Socket 478/LGA775 | |
| 0.09 | 800-1066 | 2.8-3.73 | 84-118 | LGA775 | |
| 0.065 | 800 | 3.0-3.8 | 80-86 | LGA775 | |
| Pentium D | 0.09 | 533-800 | 2.8-3.2 ГГц | 115-130 | LGA775 |
| 0.065 | 80-1066 | 3.4 ГГц | 95-130 | LGA775 | |
| Core 2 Duo | 0.065 | 80-1066 | 1.8-2.66 ГГц | 45-65 | LGA775 |
| Core 2 Extreme | 0.065 | 1066 | 2.9-3.2 ГГц | 75 | LGA775 |
| Xeon | 0.18 | 100 | 400 | Slot2 | |
| 0.13 | 100-133 | 500-733 | |||
| 0.09-0.65 | 1.4-1.7 ГГц | ||||
| Celeron | 0.25 | 66 | 266-300 | 16-18 | Slot 1 |
| 0.25 | 66 | 300-533 | 19-26 | Socket 370/Slot 1 | |
| 0.18 | 100 | 533-1.1 ГГц | 11-33 | Socket-370 | |
| 0.13 | 100 | 1.0-1.4 | 27-35 | S 370 | |
| 0.18 | 400 | 1.7-1.8 ГГц | 63-66 | S478 | |
| 0.13 | 400 | 2.0-2.8 ГГц | 59-68 | S 478 | |
| Celeron D | 0.09 | 533 | 2.133-3.33 ГГц | 73-84 | S478/LGA775 |
| 0.065 | 533 | 3.33 ГГц | 86 | LGA775 | |
| Itanium | 0.18 | 733-800 | 800-1.0 ГГц | ||
| Itanium 2 | 0.13 | 1.5 ГГц | |||
| Itanium (двухъядерный) | 0.09 | 2 x 667 | 1.4-1.6 ГГц | 75-104 |
Ядро Core
Основное исполнительное устройство. Производительность МП при тактовой частоте 66 МГц составляет около 112 миллионов команд в секунду (MIPS). Пятикратное повышение (по сравнению с 80486 DX) достигалось благодаря двум конвейерам, позволяющим выполнить одновременно несколько команд. Это два параллельных 5-ступенчатых конвейера обработки целых чисел, которые позволяют читать, интерпретировать, исполнять две команды одновременно.
Старый процессор также известен как центральный процессор. Этот элемент прочитал инструкции и данные и обработал их, что привело к результатам. Ядро является основной частью этого устройства, в частности, которое отвечает за выполнение инструкций. Прежде чем они могли интегрировать два или более ядра внутри чипа, было многопроцессорное оборудование. В них было несколько микросхем на одной материнской плате, но они были очень дорогими и нуждались в специальных пластинах, чтобы заставить их работать.
Идея ядра по сути одна и та же, но гораздо более эффективная, чтобы быть включенной в один и тот же чип. Тогда мы увидим, что самые современные микропроцессоры составляют до 9 ядер. Здесь вы найдете описание типов и характеристик микрофонов, изготовленных этими производителями. Ниже у вас есть новейший из двух производителей микропроцессоров.
- а - Pentium ММХ, интерфейс Socket 7;
- б - Celeron, упаковка Single Edge Processor Package (SEPP)/Slot 1;
- в - AMD Athlon (формат Slot А);
- г - основные компоненты процессора Pentium.
Команды над целыми числами могут выполняться за один такт синхронизации. Эти конвейеры неодинаковы: U-конвейер выполняет любую команду системы команд семейства 86; V-конвейер выполняет только «простые» команды, то есть команды, которые полностью встроены в схемы МП и не требуют микропрограммного управления (microcode) при выполнении.
Процессор - это модуль, который обеспечивает интерпретацию и выполнение программ. Внутри он содержит: блок управления; арифметико-логическое единство; регистры. Это отдельные типы параллельных процессоров, обычно два или более процессора могут совместно использовать другие системные ресурсы одинаково, независимо друг от друга, но операционная система должна координировать работу.
Затем процессор переходит в реальный цикл. Фаза выборки создает загрузку следующей команды, которая должна быть выполнена. Инструкция находится в памяти в виде кода машинного языка, который должен быть надлежащим образом «распознан» процессором и выполнен. Фаза сборки операнда собирает любые операнды, необходимые для выполнения текущей команды. Фаза выполнения заключается в фактическом выполнении текущей команды на собранных операндах.
Для постоянной загрузки этих конвейеров из кэш памяти требуется широкая полоса пропускания. Естественно, для отмеченного случая совмещенный буфер команд и данных не подходит. Pentium имеет разделенный буфер команд и данных - двухвходовые (атрибут RISC-процессоров). Обмен данными через кэш данных выполняется совершенно независимо от процессорного ядра, а буфер команд связан с ним через высокоскоростную 256-разрядную внутреннюю шину. Каждая кэш память имеет емкость 8 Кбайт, и они допускают одновременную адресацию. Поэтому программа в одном такте синхронизации может извлечь 32 байта (256: 8=32) команд и произвести два обращения к данным (32 х 2=64).
Такты работы процессора
Чтобы повысить производительность системы, вы можете. Фактически, улучшение скорости обработки чипов имеет встроенные часы, которые имеют функцию установления скорости всех операций, выполняемых компьютером, эта скорость измеряется в мегагерцах, как правило, чем выше тактовая частота и тем выше скорость процессор.
Для проведения реальных сравнений между системами были разработаны специальные тестовые программы, которые можно запускать на разных типах компьютеров; скорость выполнения программы в системе должна указывать скорость самой системы. Однако этот метод не работает должным образом.
Предсказатель переходов (Branch Predictor)
Пытается угадать направление ветвления программы и заранее загрузить информацию в блоки предвыборки и декодирования команд.
Буфер адреса переходов (Branch Target Buffer ВТВ)
Буфер адреса переходов обеспечивает динамическое предсказание переходов. Он улучшает выполнение команд путем запоминания состоявшихся переходов (256 последних переходов) и с опережением выполняет наиболее вероятный переход при выборке команды ветвления. Если предсказание верно, то эффективность увеличивается, а если нет, то конвейер приходится сбрасывать полностью. Согласно данным Intel, вероятность правильного предсказания переходов в процессорах Pentium составляет 75-90 %.
Микропроцессор представляет собой многофункциональную интегральную схему, которая в основном соответствует компьютеру. Он играет роль менеджера, который координирует деятельность различных частей компании. Блок декодирования просто выполняет то, что подразумевает название: декодирование входных инструкций в их простейшей форме. Шина, термин, с которой вызывается связь между компьютером и процессором, содержит сигналы, адреса и данные, которые передаются между различными компонентами компьютера. Хотя аналогия не идеальна, автобус можно сравнить с предпочтительными полосами городского трафика.
Блок плавающей точки (Floating Point Unit)
Выполняет обработку чисел с плавающей точкой. Обработка графической информации, мультимедиа-приложений и интенсивное использование персонального компьютера для решения вычислительных задач требуют высокой производительности при выполнении операций с плавающей точкой. Аппаратная реализация (вместо микропрограммной) основных арифметических операций (+, х и /) выполняется автономными высокопроизводительными блоками, и 8-ступенчатый конвейер позволяет выдавать результаты через каждый такт.
Размер шины определяет объем данных, которые могут быть переданы. Очевидно, что 64-разрядная шина содержит больше данных, чем один бит 16 бит. Внутри компьютера имеется несколько автобусных структур, наиболее важные структуры перечислены ниже. Сигналы указать, когда данные готовы для чтения, когда определенное устройство хочет использовать шины и тип операции, которые должны для выполнения. При исследовании недавно построенного микропроцессора часто рассматривается микропроцессорная упаковка, а не микропроцессор, содержащийся в керамическом или пластиковом корпусе.
Кэш память 1-го уровня (Level 1 cache)
Процессор имеет два банка памяти по 8 Кбайт, 1-й - для команд, 2-й - для Данных, которые обладают большим быстродействием, чем более емкая внешняя кэш память (L2 cache).
Интерфейс шины (Bus Interface
Передает в центральный процессор поток команд и данных, а также передает данные из центрального процессора.
Основные характеристики процессоров
Первые микропроцессоры охлаждались потоком воздуха, создаваемого системным вентилятором. Этот тип охлаждения назывался лучистым. Вся теплота, излучаемая процессором, охлаждалась воздухом, который был вызван в случае вентилятора источника питания. Начиная с процессора 486, процессоры были охлаждены радиатором или охлаждающим вентилятором процессора или обоими, подключенными непосредственно к поверхности процессора. Кроме того, воздушный поток вентилятора системы был отменен, чтобы нагретый воздух перетекал изнутри корпуса наружу.
В процессоре Pentium введен режим управления системой SMM (System Management Mode). Этот режим дает возможность реализовывать системные функции очень высокого уровня, включая управление питанием или защиту, прозрачные для операционной системы и выполняющихся приложений.
Pentium Pro (1 ноября 1995 года)
Pentium Pro (шестое поколение МП) имеет три конвейера, каждый из которых включает 14 ступеней. Для постоянной загрузки имеется высокоэффективный четырехвходовый кэш команд и высококачественная система предсказания ветвлений на 512 входов. Дополнительно для повышения производительности была применена буферная память (кэш) второго уровня емкостью 256 Кбайт, расположенная в отдельном чипе и смонтированная в корпусе центрального процессора. В результате стала возможной эффективная разгрузка пяти исполнительных устройств: два блока целочисленной арифметики; блок чтения (load); блок записи (store); FPU (Floating-Point Unit - устройство арифметических операций с плавающей точкой).
Некоторые новые процессоры имеют рабочую температуру от 85 до 100 градусов Цельсия, что, безусловно, высоко. Очень важно помнить, что охлаждение процессора должно поддерживаться при ожидаемой рабочей температуре. При слишком высоких температурах процессора производительность процессора начинает ухудшаться: он останавливается или может быть постоянно поврежден. Радиаторы и вентиляторы они предназначены для выпуска тепла из упаковки через ребра радиатора и поток воздуха вентилятора.
Процессоры Pentium Хеоn
Как правило, процессор не является единственным высокотемпературным устройством внутри корпуса компьютера. Другие высокопроизводительные устройства, такие как ускоренные видеокарты и высокоскоростные диски, могут выделять большое количество тепла. Корпус компьютера должен обеспечивать достаточную вентиляцию, чтобы холодный воздух мог втягиваться в горячий воздух и был исключен, иначе это сократит срок службы компьютера.
Pentium Р55 (Pentium ММХ)
8 января 1997 года Pentium ММХ -версия Pentium с дополнительными возможностями. Технология ММХ должна была добавить/расширить мультимедийные возможности компьютеров. ММХ объявлен в январе 1997 года, тактовая частота 166 и 200 МГц, в июне того же года появилась версия 233 МГц. Технологический 0.35-мкм процесс, 4.5 миллионов транзисторов.
Принципы работы процессора
Микропроцессоры подключены к материнской плате компьютера. Для подключения процессора к материнской плате используются два основных типа системы крепления: разъем и слот. Некоторые процессоры доступны только в определенном типе; другие доступны в обоих случаях. Используемый тип зависит от предпочтений производителя; оба имеют совсем другой вид, но функции почти схожи.
Ниже приведен список из 10 наиболее часто используемых сокетов. Этот общий интерфейс обычно ограничивал тактовую частоту шины. . Существует четыре типа слотов для подключения микропроцессоров к материнским платам. Тактовые скорости измеряются в мегагерцах миллионы циклов в секунду. Компьютер с частотой 5 МГц может обрабатывать пять миллионов циклов в секунду. Чем больше число циклов в секунду, поддерживаемых компьютером, тем больше количество команд, которые компьютер может выполнить.
Pentium 2 (7 мая 1997 года)
Процессор представляет собой модификацию Pentium Pro с поддержкой возможностей ММХ. Была изменена конструкция корпуса - кремниевую пластину с контактами заменили на картридж, увеличена частота шины и тактовая частота, расширены ММХ-команды. Первые модели (233-300 МГц) производились по 0.35-мкм технологии, следующие - по 0.25-мкм. Модели с частотой 333 МГц выпущены в январе 1998 года и содержали 7.5 миллионов транзисторов. В апреле того же года появились версии 350 и 400 МГц, а в августе - 450 МГц. Все Р2 имеют кэш второго уровня объемом 512 Кбайт. Есть также модель для ноутбуков - Pentium 2 РЕ, а для рабочих станций - Pentium 2 Хеоn 450 МГц.
Полезно подчеркнуть тот факт, что каждый вывод сконструирован для определенного значения или функции. Это общий аспект микропроцессоров и интегральных схем. Этот процессор также представил множество инноваций, таких как включение кэш-памяти процессора в процессорной микросхеме, введение доступа к пакетной памяти и впервые интегрированный математический сопроцессор.
До недавнего времени это был один из самых мощных процессоров на рынке. Что такое процессор? является электронным процессором - системой, ответственной за управление другими системами или элементами, обычно компьютером. Процессор получает инструкции, которые он выполняет. Различают аппаратные и программные процессоры. Программный процессор - это программа, которая изменяет команды, которые выходят на выход. В контексте программных процессоров часто используется термин «текстовая обработка». В приведенном ниже тексте речь идет только об аппаратных процессорах.
Pentium 3 (26 февраля 1999 года)
РЗ - один из самых мощных и производительных процессоров Intel, но в своей конструкции он мало чем отличается от Р2, увеличена частота и добавлено около 70 новых команд (SSE). Первые модели объявлены в феврале 1999 года, тактовые частоты - 450.500, 550 и 600 МГц. Частота системной шины 100 МГц, 512 Кбайт кэша второго уровня, технологический 0.25-мкм процесс, 9.5 миллионов транзисторов. В октябре 1999 года также выпущена версия для мобильных компьютеров, выполненная по 0.18-мкм технологии с частотами 400.450, 500.550, 600.650, 700 и 733 МГц. Для рабочих станций и серверов существует РЗ Хеоn, ориентированный на системную логику GX с объемом кэша второго уровня 512 Кбайт, 1 Мбайт или 2 Мбайт.
Применение процессоров. Процессоры чаще всего используются во встроенных системах, то есть в компьютерах, встроенных в техническое устройство. Встраиваемые системы также включают устройства бытовой электроники. На настольном компьютере основной процессор управляет последующими встроенными процессорами.
На разговорном языке термины основной процессор и процессор часто используются синонимом. Основной процессор - это самый важный элемент компьютера. В настоящее время большинство основных процессоров расположены в микросхеме - отсюда и концепция микропроцессора. Многоядерные процессоры также относятся к микропроцессорной группе.
Pentium 4 (Willamette, 2000 года; Northwood, 2002 года)
Семейства Pentium 2, Pentium 3 и Celeron имеют одинаковое строение ядра, отличаясь в основном размером и организацией кэша второго уровня и наличием набора команд SSE, появившегося в Pentium 3.
Достигнув частоты в 1 ГГц, Intel столкнулась с проблемами в дальнейшем наращивании частоты своих процессоров - Pentium 3 на 1.13 ГГц даже пришлось отзывать в связи с его нестабильностью.
В этом случае в одной микросхеме есть много процессорных блоков, которые работают вместе как процессор. Процессоры для ноутбуков Процессоры ноутбуков, также известные как процессоры мобильных устройств, в основном используются в ноутбуках, таких как ноутбуки или нетбуки. По сравнению с процессорами, используемыми на настольных компьютерах, процессоры ноутбуков более энергоэффективны, поскольку их ядра питаются от более низкого напряжения, которое при необходимости может быть быстро увеличено. При вводе напряжение между двумя нажатиями клавиш уменьшается, например, для снижения энергопотребления.

- a - Willamette, 0.18 мкм;
- б - Northwood, 0.13 мкм;
- в - Prescott, 0.09 мкм;
- г - Smithfield (2 х Prescott 1М)
Проблема в том, что латентности (задержки), возникающие при обращении к тем или иным узлам процессора, в Р6 уже слишком велики. Таким образом появился Pentium IV - в его основе лежит архитектура, названная Intel NetBurst architecture.
Основными компонентами ЦП являются
Потребление энергии ноутбуков также значительно ниже, что означает, что срок службы ноутбуков и нетбуков больше. Процессоры ноутбуков часто имеют больше вычислительной мощности, чем процессоры во встроенных системах, поэтому они подходят для мультимедийных и офисных приложений. Благодаря их хорошей производительности они также используются в промышленных установках и кассовых аппаратах. Мобильные процессоры обычно дороже настольных процессоров. Другие типы процессоров Асинхронные процессоры состоят из нескольких блоков, которые работают независимо друг от друга, поэтому для обработки данных они не требуют централизованной тактовой частоты.
Архитектура NetBurst имеет в своей основе несколько инноваций, в комплексе позволяющих добиться конечной цели - обеспечить запас быстродействия и будущую наращиваемость для процессоров семейства Pentium IV. В число основных технологий входят:
- Hyper Pipelined Technology - конвейер Pentium IV включает 20 стадий;
- Advanced Dynamic Execution - улучшенное предсказание переходов и исполнение команд с изменением порядка их следования (out of order execution);
- Trace Cache - для кэширования декодированных команд в Pentium IV используется специальный кэш;
- Rapid Execute Engine - ALU процессора Pentium IV работает на частоте, вдвое большей, чем сам процессор;
- SSE2 - расширенный набор команд для обработки потоковых данных;
- 400 МГц System Bus - новая системная шина.
Pentium IV Prescott (февраль 2004 года)
В начале февраля 2004 года Intel анонсировала четыре новых процессора Pentium IV (2.8; 3.0; 3.2 и 3.4 ГГц), основанных на ядре Prescott, которое включает ряд нововведений. Вместе с выпуском четырех новых процессоров Intel представила процессор Pentium IV 3.4 ЕЕ (Extreme Edition), основанный на ядре Northwood и имеющий 2 Мбайт кэш памяти третьего уровня, а также упрощенную версию Pentium IV 2.8 А, основанную на ядре Prescott с ограниченной частотой шины (533 МГц).
Поэтому команды могут быть переданы на другое устройство в любое время. Для обработки больших битовых строк сразу несколько процессоров вложены в сегментный процессор. Сигнальные процессоры преобразуют аналоговые сигналы с использованием цифровых систем.
Входные и выходные устройства управляются процессорами ввода и вывода. Графический процессор обрабатывает графические данные. Аудиопроцессор вычисляет аудиоданные. Числа с плавающей запятой обрабатываются сопроцессором, который ранее был отдельным чипом и теперь является частью основного процессора.
Prescott выполнен по технологии 90 нм, что позволило уменьшить площадь кристалла, причем число транзисторов было увеличено более чем в 2 раза. В то время как ядро Northwood имеет площадь 145 квадратных миллиметров и на нем размещено 55 миллионов транзисторов, ядро Prescott имеет площадь 122 квадратных миллиметров и содержит 125 миллионов транзисторов.
Перечислим некоторые отличительные особенности процессора.
Новые SSE-команд
Intel представила в Prescott новую технологию SSE3, которая включает 13 новых потоковых команд, которые увеличат производительность некоторых операций как только программы начнут их использовать. SSE3 является не просто расширением SSE2, так как добавляет новые команды, но и позволяет облегчить и автоматизировать процесс оптимизации готовых приложений средствами компилятора. Другими словами, разработчику программного обеспечения не надо будет переписывать код программы, необходимо будет только перекомпилировать ее.
Увеличенный объем кэш памят
Одним из важнейших (с точки зрения производительности) дополнений можно считать увеличенный до 1 Мбайт кэш второго уровня. Объем кэш памяти первого уровня также был увеличен до 16 Кбайт.
Улучшенная предвыборка данны
Ядро Prescott имеет улучшенный механизм предвыборки данных.
Улучшенный Hyperthreadin
В новую версию включено множество новых особенностей, способных оптимизировать многопоточное выполнение различных операций. Единственный недостаток новой версии заключается в необходимости перекомпиляции программного обеспечения и обновления операционной системы.
Увеличенная длина конвейер
Для увеличения рабочей частоты будущих процессоров ядро Prescott имеет увеличенную с 20 до 31 ступени длину конвейера. Увеличение длины конвейера негативно сказывается на производительности в случае неправильного предсказания ветвлений. Для компенсации увеличения длины конвейера была улучшена технология предсказания ветвлений.
Проблемы архитектуры NetBurst
Выпуск ядра Prescott, для которого Intel использовала технологический 90 нанометровый процесс, вскрыл ряд труднопреодолимых проблем. Первоначально NetBurst была объявлена специалистами Intel как архитектура с существенным запасом производительности, который со временем можно будет реализовать посредством постепенного наращивания тактовой частоты. Однако на практике оказалось, что увеличение тактовой частоты процессора влечет за собой неприемлемое возрастание тепловыделения и энергопотребления. Причем происходящее параллельно развитие технологии производства полупроводниковых транзисторов не позволяло эффективно бороться с ростом электрических и тепловых характеристик. В результате третье поколение процессоров с архитектурой NetBurst (Prescott) осталось в истории процессоров как одно из самых «горячих» (процессоры, построенные на этом ядре, могли потреблять и соответственно выделять до 160 Вт, получив кличку «кофеварки»), при том, что их тактовая частота не поднялась выше 3.8 ГГц. Высокое тепловыделение и энергопотребление вызвали множество смежных проблем. Процессоры Prescott требовали использования специальных материнских плат с усиленным стабилизатором напряжения и особых систем охлаждения с повышенной эффективностью.
Проблемы с высоким тепловыделением и энергопотреблением были бы не столь заметны, если бы не то обстоятельство, что при всем при этом процессоры Prescott не смогли продемонстрировать высокой производительности, благодаря которой можно было бы закрыть глаза на упомянутые недостатки. Заданный конкурирующими процессорами AMD Athlon 64 уровень быстродействия оказался для Prescott практически недостижимым, в результате этого данные центрального процессора стали восприниматься как провал Intel.
Поэтому не вызвало особого удивления, когда оказалось, что преемники NetBurst будут основываться на принципе эффективного энергопотребления, принятом в мобильной микроархитектуре Intel и воплощенном в семействе процессоров Pentium М.
Smithfield
По существу, ядро центрального процессора Smithfield - не более чем пара кристаллов Prescott 1М (90 нм), связанных вместе. Каждое ядро имеет собственную кэш память L2 (1 Мбайт), к которой может обратиться другое ядро через специальную интерфейсную шину. Результат - кристалл 206 квадратных миллиметров, содержащий 230 миллионов транзисторов.
Все двухъядерные чипы настольных персональных компьютеров, как ожидается, будут поддерживать технологии, введенные в последние месяцы 2004 года как инновации Pentium 4 Extreme Edition - ЕМ64Т, E1ST, XD bit и Vandepool:
- технология «Увеличенная Память 64» (Enhanced Memory 64 - EM64T) обеспечивает расширения на 64 бита архитектуры х86; Enhanced Intel SpeedSTep (EIST) идентичен механизму, осуществленному в процессорах Intel мобильных персональных компьютеров, который позволяет процессору уменьшать его тактовую частоту, когда не требуется высокая загрузка, таким образом значительно сокращая нагрев центрального процессора и потребление мощности; XD bit - технология «невыполнимых битов» EXecute Disable Bit - NX-битов;
- Vandepool-технология Intel (также известна как технология виртуализации - VT) позволяет одновременно выполнять несколько операционных систем и приложений в независимых разделах памяти, при этом единственная компьютерная система функционирует как несколько виртуальных машин.
В мае 2005 года вышли три чипа Pentium D Smithfield со скоростями 2.8, 3.0 и 3.2 ГГц и номерами моделей 820.830 и 840 соответственно.
Pentium D. Первые чипы Pentium D, представленные в мае 2005 года были построены на 90 нанометровой технологии Intel и имели номера моделей в ряду 800. Самый быстрый из выпущенных центральных процессоров имел скорость 3.2 ГГц. В начале 2006 года был выпущен образец Pentium D с номерами 900 и кодовым наименованием «Presler», изготовленный на технологическом 65 нанометров процессе Intel.
Чипы Presler включают пару ядер Cedar Mill. Однако, в отличие от предыдущего Pentium D Smithfield, здесь два ядра физически разделены. Включение двух дискретных кристаллов в единый пакет обеспечивает гибкость производства, позволяя использовать тот же самый кристалл как для одноядерного Cedar Mill, так и для двухядерного центрального процессора Presler. Кроме того, производственные расходы улучшаются, поскольку при обнаружении дефекта выбраковывается только один кристалл, а не двухядерный пакет.

- а - Smithfield;
- 6 - Presler.
Новая технология позволила увеличить не только тактовую частоту, но также и число транзисторов на кристалле. Как следствие, Presler имеет 376 миллионов транзисторов сравнительно с 230 миллионов для Smithfield. В то же самое время размер кристалла был уменьшен c 206 до 162 квадратных миллиметров. В результате удалось увеличить кэш память L2 Presler. В то время как его предшественник использовал две кэш памяти L2 по 1 Мбайт, процессоры Presler включают модули кэш памяти L2 по 2 Мбайта. Размещение нескольких ядер центрального процессора на одном кристалле имеет преимущество - кэш память может работать при намного более высокой частоте.
К весне 2006 года самый быстрый объявленный чип основного направления Pentium D был моделью 950 с частотой 3.4 ГГц. Считается, что Pentium D будет последним процессором, несущим фирменный знак Pentium, основного изделия Intel с 1993 года
Процессоры Pentium Хеоn
В июне 1998 года Intel начинает выпускать центральный процессор Pentium 11 Хеоn, работающий на частоте 400 МГц. Технически Хеоn представлял собой комбинацию технологий Pentium Pro и Pentium 2 и был разработан, чтобы предложить повышенную эффективность, требуемую в критических приложениях для рабочих станций и серверов. Используя интерфейс Slot 2, Хеоn имели почти вдвое больший размер, чем Pentium 2, прежде всего из-за увеличенной кэш памяти L2.
В ранних образцах чип снабжался кэш памятью L2 на 512 Кбайт или 1 Мбайт. Первый вариант был предназначен для рынка рабочих станций, второй - для серверов. Версия на 2 Мбайт вышла позже, в 1999 году Подобно центральному процессору Pentium 2 на 350-400 МГц, FSB (первичная шина) работала на частоте 100 МГц.
Основное усовершенствование сравнительно с Pentium 2 - кэш память L2 работала на частоте ядра центрального процессора, в отличие от конфигураций на основе Slot 1, которые ограничивали кэш L2 половиной частоты центрального процессора, что позволяло Intel использовать более дешевую память Burst SRAM в качестве кэша, вместо того чтобы применять обычную SRAM.
Другое ограничение, которое удалось преодолеть посредством Slot 2, был «двухпроцессорный предел». При использовании архитектуры SMP (симметрический мультипроцессор) процессор Pentium 2 оказался неспособен поддерживать системы с более чем двумя центральными процессорами, в то время как системы, основанные на Pentium 2 Хеоn, могли объединять четыре, восемь или более процессоров.
В дальнейшем были разработаны различные системные платы и чипсеты для АРМ и серверов - 440GX был построен на базе основной архитектуры чипсета 440ВС и предназначен для рабочих станций, a 450NX, с другой стороны, был разработан в основном для рынка серверных применений.
Вскоре после выхода Pentium 3 весной 1999 года был выпущен Pentium 3 Хеоn (кодовое имя Tanner). Это был базовый Pentium Хеоп с добавлением нового набора команд Streaming SIMD Extensions (SSE). Нацеленный на рынок серверов и рабочих станций, Pentium 3 Хеоп первоначально выпускался на 500 МГц и с кэш памятью L2 512 Кбайт (или 1.0-2.0 Мбайт). Осенью 1999 года Хеоn начал выпускаться с ядром «Cascade» (0.18 мкм), со скоростями, увеличивающимися от начальных 667 МГц до 1 ГГц к концу 2000 года
Весной 2001 года выпущен первый Хеоn на основе Pentium IV со скоростями 1.4, 1.5 и 1.7 ГГц. Базирующийся на ядре Foster, он был идентичен стандарту Pentium IV, за исключением разъема microPGA Socket 603.
Itanium (архитектура IA-64)
Данная архитектура была объявлена Intel в мае 1999 года Типичным представителем архитектуры является центральный процессор Itanium. Процессоры IA-64 располагают мощными вычислительными ресурсами, включая 128 регистров для целых чисел, 128 регистров с плавающей запятой, и 64 регистра предикации наряду с множеством регистров специального назначения. Команды должны группироваться для параллельного выполнения различными функциональными модулями. Набор команд оптимизирован, чтобы обеспечить вычислительные потребности криптографии, видеокодирования и других функций, которые все более необходимы следующим поколениям серверов и рабочих станций. В процессорах IA-64 также поддерживаются и развиваются ММХ-технологии и SIMD-расширения.
Архитектура IA-64 не является ни 64-битовой версией архитектуры Intel IA-32, ни адаптацией предложенной Hewlett-Packard архитектуры PA-RISC на 64 бита, а представляет собой полностью оригинальную разработку. IA-64 - это компромисс между CISC и RISC, попытка сделать их совместимыми - существуют два режима декодирования команд - VLIW и CISC. Программы автоматически переключаются в необходимый режим исполнения.
Основные инновационные технологии IA-64: длинные слова команд (long instruction words - LIW), предикаты команд (instruction predication), устранение ветвлений (branch elimination), предварительное чтение данных (speculative loading) и другие ухищрения для того, чтобы «извлечь больше параллелизма» из кода программ.
![]()
Таблица основных различий архитектур IA-32 и IA-64
Основная проблема архитектуры IА-64 заключается в отсутствии встроенной совместимости с х86 кодом, что не позволяет процессорам IA-64 эффективно работать с программным обеспечением, разработанным за последние 20-30 лет. Intel оборудует свои процессоры IA-64 (Itanium, Itanium 2 и так далее) декодером, который преобразует инструкции х86 в команды IA-64.
Процессор выполняет следующие функции:
1) вычисление адресов команд и операндов;
2) выборку и дешифрацию команд из оперативной памяти;
3) выборку данных из оперативной памяти, микропроцессорной памяти и регистров адаптеров внешних устройств;
4) приём и обработку запросов и команд от внешних устройств;
5) обработку данных и их запись в оперативную память, регистры микропроцессора и регистры адаптеров внешних устройств;
6) выработку управляющих сигналов для всех прочих узлов и блоков компьютера;
7) переход к следующей команде.
Согласно /4/, основными параметрами микропроцессоров являются: разрядность , рабочая тактовая частота , размер кэш-памяти , состав инструкций , конструктив.
1) Разрядность внутренних регистров – количество бит, которые процессор способен обработать за один приём. Разрядность шины данных определяет количество разрядов, над которыми одновременно могут выполняться операции. Разрядность шины адреса определяет объём памяти (адресное пространство), с которым может работать процессор. Адресное пространство – это максимальное количество ячеек памяти, которое может быть непосредственно адресовано микропроцессором.
2) Рабочая тактовая частота (МГц) во многом определяет быстродействие процессора, поскольку каждая команда выполняется за определённое число тактов. Чем короче машинный такт, тем выше производительность процессора. Быстродействие компьютера также зависит и от тактовой частоты шины системной платы, с которой работает процессор.
3) Кэш-память , устанавливаемая на плате микропроцессора, имеет два уровня:
3.1) L 1 – память первого уровня, находящаяся внутри основной микросхемы (ядра) процессора и работающая всегда на полной частоте процессора (впервые появилась в микропроцессорах Intel 386SLC и 486).
3.2) L 2 – память второго уровня, кристалл, размещаемый на плате микропроцессора и связанный с ядром внутренней шиной (впервые введена в микропроцессорах Pentium II). Эта память может работать на полной или половинной частоте процессора.
4) Состав инструкций – перечень, вид и тип команд, автоматически выполняемых микропроцессором. Определяет непосредственно те процедуры, которые могут выполняться над данными и те категории данных, над которыми могут выполняться эти процедуры. Существенное изменение состава инструкций произошло в микропроцессорах Intel 80386 (этот состав принят за базовый), Pentium MMX, Pentium III, Pentium 4.
5) Конструктив подразумевает те физические разъёмные соединения, в которые устанавливается микропроцессор. Разные разъёмы имеют различную конструкцию (щелевой разъём – Slot, разъём-гнездо – Soket), разное количество контактов.
Процессоры классифицируются по различным признакам. В соответствии с /4, 13/, можно выделить следующие основные признаки:
1) По назначению микропроцессоры делятся на универсальные и специализированные . Первые предназначены для решения широкого круга задач, в системе команд заложена алгоритмическая универсальность. Таким образом, производительность процессора слабо зависит от специфики решаемых задач. Специализированные процессоры предназначены для решения определённого круга задач или даже одной задачи, имеют ограниченный набор команд. Среди них выделяются процессоры для обработки данных , математические процессоры и микроконтроллеры .
2) По количеству выполняемых программ процессоры подразделяются на однопрограммные (переход к выполнению следующей программы происходит только после завершения текущей программы) и мультипрограммные (одновременно выполняются несколько программ).
3) По структурному признаку выделяют микропроцессоры с фиксированной разрядностью (имеют строго определённую разрядность) и микропроцессоры с наращиваемой разрядностью (позволяют секциями увеличивать число разрядов).
4) По числу БИС (СБИС) в микропроцессорном комплекте можно выделить однокристальные , многокристальные и многокристальные секционные процессоры. В первом случае все аппаратные части процессора реализованы в виде одной БИС (СБИС); возможности таких процессоров ограничены ресурсами кристалла и корпуса. Многокристальные процессоры получаются в результате разбиения логической структуры процессора на функционально законченные части, каждая из которых реализована в виде БИС или СБИС. В последнем случае функционально законченные части логической структуры процессора разбиваются на секции, которые реализованы в виде БИС.
5) По разрядности обрабатываемой информации микропроцессоры могут быть 4, 8, 12, 16, 24, 32 и 64-разрядными. На практике наибольшее распространение имеют 32-разрядные процессоры; всё большее применение находят 64-разрядные процессоры.
6) По виду технологии изготовления БИС (СБИС) микропроцессоры делятся на две группы: процессоры, построенные на БИС, изготовленных по униполярной технологии , и процессоры, построенные на БИС, изготовленных по биполярной технологии . Представители первой группы: p -канальные (p -МОП) , n -канальные (n -МОП) , комплиментарные (КМОП) БИС. (МОП – металл-окисел-проводник). Ко второй группе относятся БИС на базе транзисторно- транзисторной логики (ТТЛ) , эмиттерно-связанной логики (ЭСЛ) и интегральной инжекторной логики (И 2 Л) . Вид технологии изготовления БИС во многом определяет степень интеграции микросхем, быстродействие, энергопотребление, помехозащищённость и стоимость процессоров. По комплексу этих признаков можно отдать предпочтение микропроцессорам, выполненным по n-МОП и КМОП- технологиям, обеспечивающим высокую плотность компоновки, высокое быстродействие и относительно малую стоимость. ЭСЛ обеспечивает самое высокое быстродействие процессоров, но низкую плотность компоновки и высокое энергопотребление. Технология И 2 Л даёт усреднённые характеристики микропроцессоров.
7) По характеру системы команд выделяют процессоры с полным набором инструкций или CISC -процессоры (Complex Instruction Set Command), процессоры с сокращённым набором инструкций или RISC -процессоры (Reduced Insrruction Set Command), процессоры со сверхбольшим командным словом или VLIW -процессоры (Very Long Instruction Word). CISC-процессоры имеют большой набор разноформатных команд, что позволяет применять эффективные алгоритмы решения задач, но, в то же время, усложняет схему процессора, и в общем случае не обеспечивает максимального быстродействия. Архитектура CISC присуща классическим процессорам. RISC-процессоры содержат набор простых, чаще всего встречающихся в программах инструкций. При необходимости выполнения более сложных команд в микропроцессоре производится их автоматическая сборка из простых команд. Все простые команды имеют одинаковый размер и на их выполнение тратится один машинный такт (на выполнение самой короткой команды из системы CISC обычно тратится четыре такта). Современные 64-разрядные RISC-процессоры выпускаются многими фирмами: Apple (PowerPC), IBM (PPC) т.д. В VLIW-процессорах одна инструкция содержит несколько операций, которые должны выполняться параллельно. Задача распределения работы между несколькими вычислительными устройствами процессора решается во время компиляции программы. Такой подход позволили уменьшить габариты процессоров и потребление энергии. Примерами VLIW-процессоров служат Itanium фирмы Intel, McKinley фирмы Hewlett-Packard и другие.
8) По числу и способу использования внутренних регистров различают аккумуляторные , многоаккумуляторные и стековые процессоры. Аккумуляторные процессоры – это процессоры с одним регистром результата. Их отличительной характеристикой является относительная простота аппаратной реализации, а также упрощённый формат команд (будут рассмотрены в следующей лекции). В командах адрес операнда в аккумуляторе не указывается, а адресуется только второй операнд. Недостатками таких процессоров является необходимость предварительной загрузки операнда в аккумулятор перед выполнением операции и невозможность непосредственной записи результата выполнения команды в произвольную ячейку памяти или регистр. В многоаккумуляторных регистрах, которыми являются большинство современных процессоров, функции регистров результата может выполнять любой регистр общего назначения или ячейка памяти. В командах оба операнда задаются явно, а результат операции чаще всего помещается на место одного из операндов. В стековых процессорах обычно используется большой аппаратный стек и дополнительный внешний стек в памяти (при нехватке аппаратного). Благодаря специальному размещению операндов в стеке обработку информации можно выполнять безадресными командами, что позволяет повысить производительность процессора и экономить память. Такие команды извлекают из стека один или два операнда, выполняют над ними соответствующую арифметическую или логическую операцию и заносят результат в вершину стека. Недостатком является необходимость предварительной подготовки данных, использующих адресные команды.
С историей развития процессоров и их сравнительной характеристикой более подробно можно ознакомится в /4, 13/. Далее рассмотрим физическую и функциональную структуру процессора.
Физическая и функциональная организация ЦП (на примере ЦП Intel 8086). ШИ.
Физическая структура процессора является достаточно сложной. В соответствии с /4/, ядро процессора содержит главный управляющий и исполняющие модули – блоки выполнения операций над целочисленными данными. К локальным управляющим схемам относятся: блок с плавающей запятой, модуль предсказания ветвлений, регистры микропроцессорной памяти, регистры кэш-памяти 1-го уровня, шинный интерфейс и многое другое.
Примечание: Под логическим ядром понимается схема, по которой сделан процессор. Физически ядро представляет собой кристалл, на котором с помощью логических элементов реализована принципиальная схема процессора.
В самом общем случае функциональную структуру процессора можно представить в виде композиции, согласно одним источникам /4, 5/, двух частей: операционного устройства (ОУ ) и шинного интерфейса (ШИ ), согласно другим /2/,- трёх блоков: операционного блока (ОБ ), управляющего блока (УБ ) и интерфейсного блока (ИБ ). Имеющиеся незначительные расхождения в количестве и названии блоков никоим образом не нарушают число и принципы функционирования компонентов процессора. Поэтому рассмотрим первый (более наглядный) вариант из источника /4/.
Упрощённая типовая структура процессора представлена на рисунке 4.1.
ОУ содержит устройство управления (УУ), арифметико-логическое устройство (АЛУ), регистр флагов, регистры общего назначения (РОН), регистры-указатели, индексные регистры. ШИ содержит адресные регистры, блок регистров (буфер) команд, узел формирования адреса, схемы управления шиной и портами. Обе части микропроцессора работают параллельно, причём ШИ работает быстрее ОУ. Рассмотрим эти блоки процессора более подробно.
ШИ предназначен для связи и согласования микропроцессора с системной шиной компьютера, а также для приёма, предварительного анализа команд выполняемой программы и формирования полных адресов операндов и команд.
Сегментные (адресные) регистры совместно с узлом формирования адреса реализуют сегментацию памяти. Команды и данные хранятся в ячейках, и их местоположение в памяти определяется адресами соответствующих ячеек. Поскольку команды и данные на уровне кодов неотличимы друг от друга, то для различия команд и данных используется их размещение в различных областях памяти – сегментах. Сегмент - это прямоугольная область памяти, характеризующаяся начальным адресом и длиной. Начальный адрес (адрес начала сегмента) – это номер (адрес) ячейки памяти, с которой начинается сегмент. Длина сегмента – это количество входящих в него ячеек памяти. Сегменты могут иметь различную длину. Все ячейки, расположенные внутри сегмента, перенумеровываются, начиная с нуля. Адресация ячеек внутри сегмента ведется относительно начала сегмента; адрес ячейки в сегменте называется смещением или эффективным адресом - EA (относительно начального адреса сегмента). Текущий сегмент можно указать с помощью загрузки соответствующего сегментного регистра:
1) CS (Code Segment ) – определяет начало текущего сегмента кода, в котором располагаются команды программы. Выборка команды производится с использованием в качестве эффективного адреса содержимого регистра IP (Instruction Pointer ) , а в качестве адреса сегмента – содержимого CS. Именно регистр IP хранит смещение адреса текущей команды программы.
2) DS (Data Segment ) – определяет начало текущего сегмента данных. Ссылки на данные (за некоторым исключением) осуществляются относительно содержимого этого регистра.
3) SS (Stack Segment ) – определяет начало текущего сегмента стека. Как правило, все адреса данных, связанных со стеком, задаются относительно содержимого этого регистра.
4) ES (Extended Segment ) – определяет начало дополнительного текущего сегмента, который обычно рассматривается как вспомогательный сегмент данных (при межсегментных пересылках).
Узел формирования адреса и регистр команд функционально входят в состав УУ и были рассмотрены выше.
При адресации устройств ввода-вывода (УВВ) сегментные регистры не используются. Взаимодействие с ними процессор осуществляет через специальное адресное пространство – порты. Каждый порт имеет номер, что соответствует адресу подключённого к нему устройства. Порту устройства соответствует аппаратура сопряжения и два регистра – для обмена данными и управляющей информацией. Схема управления шиной и портами выполняет следующие функции:
1) формирование адреса порта и управляющей информации для него;
2) приём управляющей информации от порта, информации о готовности порта и его состоянии;
3) организация сквозного канала в системном интерфейсе для передачи данных между портом УВВ и процессором.
Схема управления шиной и портами использует для связи с портами системную шину: шину адреса, шину данных и шину инструкций.
Физическая и функциональная организация ЦП (на примере ЦП Intel 8086). ОУ.
В целом ОУ выполняет операции, определяемые командами, и формирует эффективные адреса.
УУ вырабатывает управляющие сигналы, поступающие во все блоки вычислительной машины. В составе УУ можно выделить следующие функциональные блоки:
1) регистр команд – запоминающий регистр, в котором хранится код команды: код операции и адреса операндов (расположен в интерфейсной части процессора);
2) дешифратор операций – логический блок, который в соответствии с поступающим из регистра команд кодом операции выбирает один из множества имеющихся у него выходов;
3) постоянное запоминающее устройство (ПЗУ) микропрограмм хранит управляющие импульсы для выполнения в блоках вычислительной машины процедур обработки информации; импульс по выбранному дешифратором операций проводу считывает из ПЗУ микропрограмм необходимую последовательность управляющих сигналов;
4) узел формирования адреса (располагается в ШИ) – устройство для вычисления полного адреса ячейки памяти (регистра) по реквизитам, поступающим из микропроцессорной памяти или регистра команд;
5) кодовые шины данных, адреса и инструкций – часть внутренней интерфейсной шины процессора.
Таким образом, УУ формирует управляющие сигналы для выполнения процессором своих функций, рассмотренных выше.
Рисунок 4.1 – Упрощённая типовая структура процессора
АЛУ предназначено для выполнения арифметических и логических операций преобразования информации. Функционально в простейшем варианте АЛУ состоит из следующих компонент:
1) сумматор выполняет процедуру сложения двоичных кодов, имеет разрядность двойного машинного слова (32 бита);
2) регистры – быстродействующие ячейки памяти различной длины: регистр 1 имеет разрядность 32 бита, регистр 2 - 16 бит; при сложении в регистр 1 помещается первое слагаемое, а потом результат, в регистр 2 – второе слагаемое;
3) схема управления принимает по кодовым шинам инструкций управляющие сигналы от УУ и преобразует в сигналы для управления работой регистров и сумматора.
АЛУ выполняет арифметические операции только над двоичными числами с фиксированной точкой. Для обработки чисел с плавающей точкой привлекается математический сопроцессор или специально составленные программы.
Более подробные сведения об устройстве и функционировании УУ и АЛУ можно найти в /3 - 5/.
Регистры ОУ – часть микропроцессорной памяти. Рассмотрим регистры на примере базового процессора Intel 8086, который содержит всего 14 двухбайтовых регистра. В современных процессорах их гораздо больше и большей разрядности. Однако в качестве базовой модели, в частности для языка Ассемблера, используется 14-регистровая память процессора.
В состав ОУ входят следующие регистры:
1) регистры общего назначения (РОН) или универсальные : AX - (AH, AL), BX - (BH, BL), CX - (CH, CL), DX - (DH, DL) могут использоваться для временного хранения любых данных, при этом можно работать с каждым регистром целиком, а можно отдельно, с каждой его половиной; но каждый из РОН может использоваться и как специальный при выполнении некоторых конкретных команд;
2) регистры смещений : SP, BP, SI, DI являются неделимыми и предназначены для хранения относительных адресов ячеек памяти внутри сегментов (смещений относительно начала сегментов);
2.1) SP (Stack Pointer ) – смещение вершины стека;
2.2) BP (Base Pointer ) – смещение начального адреса поля памяти, непосредственно отведённого под стек;
2.3) SI (Source Index ) , DI (Destination Index ) предназначены для хранения адресов индекса источника и приёмника данных при операциях над строками и им подобных.
Слово состояния процессора (PSW – Processor State Word ) или регистр флагов – имеет размер 2 байта и содержит одноразрядные признаки или флаги. Всего в регистре 9 флагов: 6 из них условные или статусные , отражают результаты операций, выполненных ОУ, остальные 3– управляющие , определяют режим исполнения программы.
1) Статусные флаги.
1.1) CF (Carry Flag ) – флаг переноса. Устанавливается в 1, если при выполнении арифметических и некоторых операций сдвига возникает «перенос» из старшего разряда.
1.2) PF (Parity Flag) – флаг чётности. Проверяет младшие 8 битов результатов над данными. Чётное число единиц приводит к установке этого флага в 1, нечётное – в 0.
1.3) AF (Auxiliary Carry Flag ) – флаг логического переноса в двоично-десятичной арифметике. Устанавливается в 1, если арифметическая операция приводит к переносу или займу четвёртого справа бита однобайтового операнда. Используется при арифметических операциях над двоично-десятичными кодами и кодами ASCII.
1.4) ZF (Zero Flag ) – флаг нуля. Устанавливается в 1, если результат операции равен 0, в противном случае ZF обнуляется.
1.5) SF (Sign Flag) – флаг знака. Устанавливается в 1, если результат арифметической операции является отрицательным, в 0, если результат положительный.
1.6) OF (Overflow Flag ) – флаг переполнения. Устанавливается в единицу при арифметическом переполнении, когда результат выходит за пределы разрядной сетки.
2) Управляющие флаги.
2.1) TF (Trap Flag ) – флаг трассировки. Единичное состояние этого флага переводит процессор в режим пошагового выполнения программы.
2.2) IF (Interrupt Flag) – флаг прерываний. При нулевом состоянии этого флага прерывания запрещены, при единичном – разрешены (о механизме прерываний речь пойдёт в следующей лекции).
2.3) DF (Direction Flag ) – флаг направления. Используется в строковых операциях для задания направления обработки данных; при единичном состояния строки обрабатываются «справа налево», при нулевом – «слева направо».
Расположение флагов в регистре PSW показано на рисунке 4.2. Свободные биты отведены для использования в будущем.
Рисунок 4.2 – Схема расположения флагов в регистре PSW
Архитектурные принципы организации RISC-процессоров.
Как отмечается в /2, 14, 15/, список команд современного микропроцессора может содержать достаточно большое число команд. Однако не все они используются одинаково часто и регулярно. Это свойство системы команд явилось предпосылкой для развития процессоров с RISC-архитектурой. Основная идея заключалась в сокращении списка используемых команд и, вследствие этого, упрощение управляющего блока процессора и для организации более быстрого исполнения оставшихся команд за счёт освободившихся при этом ресурсов кристалла.
Первые процессоры с сокращённым набором команд были реализованы в начале 80-х годов 20 века /2/:
1) В 1980 году в калифорнийском университете города Беркли под руководством профессоров Давида Паттерсона (David Patterson) и Карло Секуина (Carlo Sequin) был разработан процессор, который получил название RISC. Были разработаны модели RISC-I, RISC-II, SOLAR.
2) В 1981 году в университете города Стэнфорда под руководством Джона Хеннеси (Dohn Hennesy) был спроектирован процессор, получивший название MIPS (Microprocessor Without Interlocked Pipeline Stages – микропроцессор без блокировки конвейера). Более подробно о сути конвейеризации будет рассмотрено в следующем вопросе лекции.
Позднее обе модели с сокращённым набором команд стали называть RISC-процессорами. Отличительной особенностью этих процессоров является большое количество РОН (порядка 256).
Кратко охарактеризуем основные принципы RISC-архитектуры /2, 15/.
1) Одинаковая длина команд . Это облегчает их выборку из основной памяти. Все команды считываются за один такт, что позволяет обрабатывать поток командных инструкций по конвейерному принципу, то есть выполняется синхронизация аппаратных частей процессора с учётом последовательной передачи управления от одного аппаратного блока к другому. В современных RISC-процессорах длина команды составляет 32 бита.
2) Сокращённый набор действий над операндами, размещёнными в памяти . Простые способы адресации памяти обеспечивают быстрый доступ к операндам в памяти. Обработка данных, реализуемая при выполнении команд RISC, никогда не совмещается с операциями чтения (записи) памяти (в отличие от многих команд CISC). Обмен операндами между памятью и регистрами выполняется специальными командами загрузки (LOAD) и запоминания (STORE). Большое количество регистров блока РОН позволяет уменьшить число обращений к памяти.
3) Выполнение всех вычислительных операций над данными, размещёнными только в РОН. Поскольку регистров много, то все скалярные переменные и даже небольшие массивы переменных чаще всего размещаются в регистрах, что позволяет ускорить обработку данных. Использование простых команд упрощает реализацию их конвейерной обработки. В среднем команды RISC выполняются за один такт.
4) Относительно простые схемы управления . Уменьшение списка команд, использование команд, реализующих только простые операции, исключение в командах обработки данных обращений к памяти позволили уменьшить расход ресурсов кристалла на управление. Благодаря этому большая площадь кристалла выделяется для размещения устройств, позволяющих увеличить общую производительность процессора: дополнительных конвейеров, увеличенной кэш-памяти 1-го уровня, большего числа РОН.
Важно отметить, что при одинаковой технологии производства RISC-процессоры имеют более высокие частоты работы по сравнению с CISC-процессорами, что является важным достоинством RISC-процессоров.
Согласно /15/, в архитектуре RISC-процессоров можно выделить следующие аппаратные блоки, образующие ступени конвейера:
1) Блок загрузки инструкций включает в себя следующие составные части: блок выборки инструкций из памяти, регистр инструкций, куда помещается команда после выборки и блок декодирования инструкций. Эта ступень называется ступенью выборки инструкций.
2) РОН совместно с блоками управления регистрами образуют вторую ступень конвейера, которая отвечает за чтение операндов команд. Операнды могут храниться в самой команде или в одном из РОН. Эта ступень называется ступенью выборки операндов.
3) АЛУ и, если в данной архитектуре реализован аккумулятор, вместе с логикой управления , которая исходя из содержимого регистра инструкций определяет тип выполняемой микрооперации. При выполнении операций условного и безусловного переходов источником данных может быть также счётчик команд. Данная ступень называется исполнительной ступенью конвейера.
4) Набор из РОН и логики записи образуют ступень сохранения данных. Здесь результаты выполнения команд записываются в РОН или основную память.
К RISC-процессорам причисляют микропроцессоры MIPS R4000, R8000, R100000 фирмы MIPS Technologies Inc., UltraSPARC I, UltraSPARC II, UltraSPARC III фирмы Sun, PowerPC фирмы IBM-Motorola, Alpha AXP фирмы DEC, PA-RISC фирмы Hewlett Packard, микроконтроллеры фирмы Microchip.
Несмотря на очевидные преимущества, RISC-процессоры «в чистом виде» не получили широкого распространения на рынке персональных компьютеров, большинство из них используется в качестве центральных процессоров рабочих станций. Однако большинство современных CISC-процессоров, например, Pentium, используют достижения RISC-архитектур, в частности, RISC-ядра для выполнения вычислительных операций.
Модели RISC-процессоров активно развиваются и совершенствуются. В настоящее время на их основе реализуются коммерчески важные продукты: SPARC- и MIPS-системы.
Более полные сведения о RISC-процессорах, особенностях их архитектуры и функционирования можно найти в /2/, специальной литературе и открытых источниках сети Интернет.
Архитектурные способы повышения производительности процессоров. Конвейерная обработка информации.
Производительность является одной из наиболее важных характеристик процессора. Согласно /2/, в общем случае она определяется количеством вычислительной работы, выполняемой в единицу времени. К важнейшим факторам, влияющим на производительность, относятся тактовая частота, число команд программы, среднее время выполнения отдельной команды. Для упрощённой оценки производительности процессора часто используют показатель, указывающий число команд, выполняемых за секунду. Он определяется как частное от деления тактовой частоты на среднее время выполнения процессором отдельной команды и измеряется в MIPS (Meg Insruction Per Second) для целочисленных задач и MFLOPS (Meg Floating Point Operations Per Second) для вычислений с плавающей точкой. При этом оценки показателя, определяющего число команд, выполняемых за секунду, проводят для операций с регистровыми операндами, не привязываясь к быстродействию основной памяти. Однако этот показатель не учитывает особенности архитектуры конкретных процессоров. Поэтому для сравнительных характеристик различных процессоров используются относительные оценки производительности, для получения которых используются специальные тестовые программы.
В соответствии с /2/, повышение производительности процессоров в большинстве случаев достигается за счёт применения специальных технологических и архитектурных решений. Технологические подходы (совершенствование технологий производства ИС, увеличение степени интеграции) были рассмотрены ранее, во второй главе. Поэтому подробнее остановимся на архитектурных способах повышения производительности процессоров. Совершенствование архитектуры процессоров, обеспечивающее повышение его производительности, в настоящее время связано, прежде всего, с развитием средств параллельной обработки данных. Здесь можно выделить следующие направления:
1) Увеличение «естественного» параллелизма – повышение разрядности обработки и передачи данных (разрядность процессоров повысилась с 4 до 32 и 64 разрядов).
2) Конвейерная (многофазная) обработка данных – вычислительный процесс делится на несколько фаз, для каждой из которых используются свои средства и буфер для хранения результата (ступень конвейера).
3) Многоэлементная обработка данных - параллельная обработка данных в нескольких операционных блоках (ОУ) процессора.
Способы параллельной обработки могут сочетаться. Например, в одном процессоре можно организовать несколько операционных блоков, в каждом из которых использовать конвейеризацию.
Рассмотрим более детально два последних направления.
При многофазной обработке, как показано на рисунке 4.3, процесс обработки данных разбивается на несколько стадий (фаз), выполняемых последовательно.
Рисунок 4.3 – Многофазная обработка данных
Между фазами имеются буферы для хранения промежуточных результатов. После выполнения первой фазы результат запоминается в буфере и начинается обработка второй фазы. Средства выполнения первой фазы освобождаются, и на них поступает следующая порция данных. Если длительность фаз обработки одинакова и составляет T / n , то при таком способе производительность системы увеличится в n раз. Этот способ соответствует конвейерной обработке.
Рассмотрим организацию конвейера на уровне исполнения машинной команды /2/. Каждый блок в конвейерной цепочке осуществляет только один этап исполнения команды. Полная обработка команды занимает несколько тактов.
Типовые этапы выполнения команды: 1) выборка команды IF (Instruction Fetch), 2) дешифрация команды ID (Instruction Decode), 3) чтение операндов RD (Read Memory), 4) исполнение заданной в команде операции EX (Execute), 5) запись результата WB (Write Back). В ходе выполнения команда продвигается по конвейеру, освобождая очередную ступень для следующей команды. Содержимое буферов, которые используются для хранения информации, передаваемой по ступеням конвейера, обновляется в каждом такте по завершению этапа исполнения очередной команды. Промежуточные буферы обеспечивают параллельную независимую работу блоков конвейерной цепочки: в то время, когда последующий блок начинает выполнять этап очередной команды, предыдущий блок может приступать к обработке следующей команды, что демонстрирует рисунок 4.4.
|
Такты работы процессора |
||||||||||
|
Команда i | ||||||||||
|
Команда i+1 | ||||||||||
|
Команда i+2 | ||||||||||
|
Команда i+3 | ||||||||||
|
Команда i+4 | ||||||||||
|
Команда i+5 | ||||||||||
Рисунок 4.4 – Конвейерная обработка команд
Следует отметить, что конвейерная обработка команд не уменьшает время выполнения отдельной команды, которое в конвейерном процессоре остаётся таким же, как и в обычном неконвейерном. Однако благодаря тому, что при конвейерной обработке большая часть вычислительного процесса в режиме одновременного выполнения команд, скорость выдачи результатов последовательно выполняемых команд увеличивается пропорционально числу ступеней конвейера. Продолжительность выполнения отдельных этапов исполнения команды в общем случае зависит от типа команды и места размещения операндов. Конвейерная обработка команд наиболее эффективна в том случае, если длительность всех фаз выполнения команды приблизительно одинаковая. К сожалению, обеспечить непрерывную работу конвейера не всегда удаётся из-за различных конфликтов: по ресурсам, по данным, по управлению. Более подробно о конфликтах – в /2, 7/.
Процессор, в котором процесс выполнения команды разбивается на 5-6 ступеней, называется обычным конвейерным процессором . Если увеличить количество ступеней конвейера, то каждая отдельная ступень будет выполнять меньшую работу, а, следовательно, содержать меньше аппаратной логики. Благодаря более коротким задержкам распространения сигналов в каждой отдельно взятой ступени конвейера достигается повышение частоты работы и соответствующее повышение производительности процессора. Процессор, имеющий конвейер существенно глубже 5-6 ступеней, называется суперконвейерным . Например, Pentium II содержит 12 ступеней, UltraSPARC III – 14 ступеней, Pentium 4 – 20 ступеней.
многоэлементная

T и в системе используется n T / n
A = B + C ; D = E + F .
суперскалярным скалярной скалярными
Архитектурные способы повышения производительности процессоров. Многоэлементная обработка информации.
Как показано на рисунке 4.5 /2/, многоэлементная обработка осуществляется на нескольких параллельно работающих ОУ. Каждый элемент выполняет свою работу, осуществляя обработку порции данных от начала до конца.

Рисунок 4.5 – Многоэлементная параллельная обработка данных
Если время выполнения работы на отдельном элементе составляет T и в системе используется n элементов, то при определённой идеализации можно ожидать, что среднее время выполнения такой работы составит T / n (реально - меньше). В современных процессорах такой способ обработки связан с понятием суперскалярной архитектуры.
Простейшим примером вычислительного параллелизма является выполнение двух команд, операнды которых не связаны между собой:
A = B + C ; D = E + F .
Поэтому обе команды можно выполнять одновременно. Для выполнения несвязанных операций в состав процессора включают набор арифметических устройств, каждое из которых обычно имеет конвейерную организацию.
Процессор, содержащий несколько ОУ, которые обеспечивает одновременное выполнение более одной скалярной команды, называется суперскалярным процессором. Команда называется скалярной , если её входные операнды и результат являются числами (скалярами). Традиционные процессоры с одним ОУ называются скалярными . В суперскалярном процессоре обработка команд распараллелена не только во времени (конвейер), но и в пространстве (несколько конвейеров). Производительность такого процессора оценивается темпом схода исполненных команд со всех его конвейеров.
В настоящее время используются два способа суперскалярной обработки. Первый способ базируется на чисто аппаратном механизме выборки несвязанных команд программы из памяти (кэш-памяти, буфера предвыборки) и параллельном запуске их на исполнение. Ответственность за эффективность загрузки параллельно функционирующих конвейеров возлагается на аппаратные средства процессора, что является основным достоинством этого способа суперскалярной обработки. В этом случае процесс трансляции программ для суперскалярного процессора ничем не отличается от трансляции программ для традиционного скалярного процессора. В соответствии с этим способом, сравнительно легко реализуются суперскалярные микропроцессоры различных семейств программно совместимые между собой. При этом не возникает проблем с использованием ранее созданного программного обеспечения. Все процессоры семейства Pentium реализованы по этому способу.
В процессорах, реализующих второй способ суперскалярной обработки, планирование параллельного исполнения нескольких команд возлагается на распараллеливающий компилятор. Сначала он анализирует исходную программу в целях выявления команд, которые могут выполняться одновременно. Затем компилятор группирует такие команды в пакеты команд – длинные командные слова (VLIW), причём, число простых команд в команде VLIW принимается равным числу исполнительных блоков процессора. Поскольку всю работу по подготовке к исполнению VLIW-команд выполняет компилятор, конфликтные ситуации при их исполнении исключаются. Такой способ суперскалярной обработки реализуется в VLIW-процессорах, имеющих статическую сперскалярную архитектуру. К сожалению, для таких процессоров требуется специальное программное обеспечение. Кроме того, программы, скомпилированные для одного поколения микропроцессоров, могут выполняться неэффективно без перекомпиляции на процессорах следующего поколения. Это требует от разработчиков программного обеспечения разработки модифицированных версий исполняемых файлов своего продукта для разных поколений процессоров. Идеи VLIW предложены российскими инженерами и учёными во главе с профессором Б.А. Бабаяном при разработке отечественной супер-ЭВМ «Эльбрус-3» (1990). В настоящее время VLIW-технология реализована в процессоре Эльбрус Е2К отечественной компании «Эльбрус Интернешнл», процессорах Crusoe фирмы Transmeta, а также в семействе сигнальных процессоров (для цифровой обработки сигналов) TMS320C60xx фирмы Texas Instruments.
Классификация и структура команд процессора.
По функциональному признаку все команды процессора можно разделить на следующие группы:
1) команды пересылки данных и ввода-вывода;
2) команды арифметических и поразрядных логических операций;
3) команды передачи управления.
Команды пересылки данных обеспечивают обмен информацией между регистрами микропроцессора, а также внешние обмены данными при передаче в процессор из памяти или устройства ввода и из процессора в память или устройство вывода. В этих командах обычно указывается направление передачи, источник и (или) приёмник данных. Например, в языке Ассемблера, к командам этой группы можно отнести команду пересылки MOV , команду загрузки LOAD , команды записи в порт и чтения из порта УВВ, IN и OUT , соответственно т.п. Также сюда часто включают команды помещения данных в стек PUSH и извлечения данных из стека POP .
В число команд арифметических и поразрядных логических операций в большинстве случаев входят команды простейших арифметических операций, например, ADD (сложить), SUB (вычесть), и логических операций, например, AND («И»), OR («ИЛИ») и т.п. К арифметическим командам также относят команды арифметических и логических сдвигов, а к командам логических операций – команды сравнения COMPARE (неразрушающего вычитания). В число команд этой группы могут входить команды сложных арифметических операций: умножение, деление (есть не во всех процессорах), команды обработки данных с плавающей точкой, команды мультимедийной обработки.
Команды передачи управления используются для изменения последовательности выполнения команд при наличии программных ветвлений: команд условных и безусловного (JMP) переходов, обращении к подпрограммам (CALL) и выхода из них (RETURN). Команды условных переходов реализуют передачи управления в зависимости от значения флагов в регистре PSW. С их помощью процессор одну из возможных ветвей продолжения программы. Обычно в системе команд имеется несколько команд условных переходов.
В современных процессорах системы команд наряду с традиционными командами, перечисленными выше, содержат в своём составе группы команд, расширяющие функциональные возможности микропроцессора по обработке информации, управлению его работой, а также обеспечивающие реализацию многозадачного защищённого режима работы.
В системы команд конкретных процессоров могут входить команды, не вписывающиеся в предложенную классификацию. Подобные команды не отражают общих принципов построения программ и рассматриваются как дополнительные.
Выполнение команды (машинной операции) разделено на более мелкие этапы - микрооперации (микрокоманды), во время которых выполняются определённые элементарные действия. Конкретный состав микроопераций определяется системой команд и логической структурой вычислительной машины. Последовательность микрокоманд, реализующих данную операцию (команду), образует микропрограмму операции. Интервал времени, в течение которого выполняется одна или одновременно несколько микроопераций, называется машинным тактом. Границы тактов задаются синхросигналами, которые вырабатываются генератором синхросигналов.
В общем случае команда микропроцессора содержит две части: операционную и адресную. В соответствии с /1/, соглашение о распределении разрядов между этими частями команды и о способе кодирования информации определяет структуру (формат) команды. В операционной части команды содержится код операции, обеспечивающий кодирование операций (где n – число двоичных разрядов, отведённых под операционную часть команды) и определяющий, какие при этом будут задействованы устройства в процессоре или вне его. В k -разрядной адресной части команды содержится информация об адресах операндов, участвующих в выполнении операции. В общем случае адресная часть команды должна содержать четыре адресных поля A 1 , A 2 , A 3 , A 4 . Они предназначены для задания адресов операндов (A1, A2), адреса результата (A3) и адреса следующей команды (A4). В качестве адресов A1,…,A3 могут использоваться адреса ячеек оперативной памяти и адреса регистров микропроцессорной памяти, в качестве адреса A4- только адреса ячеек оперативной памяти. При использовании полного набора адресов формат команды оказывается громоздким. Было отмечено, что не для всех операций необходим полный набор адресов A1-A4. В зависимости от указываемого числа адресов команды подразделяются на 0-адресные (безадресные) , 1-адресные , 2-адресные , 3-адресные и 4-адресные .
Практически во всех микропроцессорах исключён адрес A4. Это обусловлено тем, что большинство команд относятся к линейным участкам алгоритмов, и такие команды могут быть размещены в ячейках памяти с последовательно возрастающими адресами. В этом случае для получения адреса следующей команды к начальному адресу сегмента кода достаточно добавить её смещение в сегменте кода, что удобно реализовать с помощью указателя команд. Такой способ адресации команд называется естественным , а реализующие его процессоры называются процессорами с естественным способом адресации команд . При нарушении естественного порядка следования команд (ветвлениях, циклах) используются специальные команды передачи управления, в которых содержится адрес перехода, но не используются адреса операндов. Процессоры, в адресном поле команд которых используется адрес A4, называются процессорами с принудительным способом адресации команд .
Использование адреса результата A3 во многих случаях также оказывается избыточным. Это обосновывается тем, что результат арифметических и логических операций над двумя операндами обычно может быть помещён на место одного из операндов, который в дальнейшем, скорее всего, использоваться не будет. При этом в 2-адресных командах в адресное поле необходимо вводить дополнительные разряды, показывающие, кто из них является источником, а кто – приёмником информации. В процессорах с аккумуляторной архитектурой число адресов в адресной части команды уменьшено до одного. В них один из операндов, размещённых в аккумуляторе, неявно задаётся кодом команды, и результат помещается в аккумулятор.
В безадресных командах осуществляется неявное задание операнда. К таким командам относятся команды управления процессором (например, пуска, останова и т.д.), команды для работы со стеком (операнд, адресуемый указателем SP, неявно задаётся кодом команды). Безадресные команды имеют предельно сокращённый формат, но не могут самостоятельно образовать функционально полную систему команд и применяются только вместе с адресными.
Формат команд влияет на время решения задач, затраты памяти, сложность процессора и зависит от класса решаемых задач. В частности, для научно- технических расчётов, в которых большой объём занимают многошаговые вычисления, более эффективными оказываются 1-адресные команды, а при использовании стекового процессора – и безадресные команды. Для задач управления, где большую долю составляют пересылки и логические операции эффективными являются 2-адресные команды. Исходя из сказанного выше, следует отметить, что в современных процессорах обычно используются безадресные, 1-адресные и 2-адресные команды. 3-адресные команды используются крайне редко, а 4-адресные не используются совсем.
Вследствие разнообразия форматов команд и данных (числа, символы, структуры и т.д.), а также их местоположения сформировались различные способы адресации команд и операндов, которые рассмотрим ниже.
Способы адресации данных. Непосредственный, прямой, косвенный, регистровый относительный режимы адресации.
Способы адресации данных определяют механизмы вычисления эффективных адресов операндов в памяти и доступа к операндам. Выделяют следующие способы (режимы) адресации /2, 6/:
1) Непосредственный – позволяет задавать фиксированные значения операнда непосредственно в адресной части команды, т.е., данное является частью команды (Рисунок 5.1). Такой режим адресации удобен при работе с константами.
Рисунок 5.1 – Непосредственная адресация
Примеры: mov ax, 5564h
add al, 1101001100b
Следует помнить, что непосредственный операнд может быть задан только как операнд-источник. Недостатком непосредственной адресации является необходимость расширения формата команд за счёт указания самого операнда в адресном поле команды.
2) Прямой – адрес операнда содержится в коде команды (Рисунок 5.2). Используется при работе с переменными и константами, местоположение которых в памяти не меняется в процессе выполнения задачи.
![]()
Рисунок 5.2 – Прямая адресация
Таким образом, в коде команды указывается смещение операнда в памяти.
Пример: d_s segment
assume ds:d_s, cs:c_s
mov ax , mm ;по адресу mm пересылается 3154h
После выполнения третьей команды в регистре ax будет записано значение по адресу mm в памяти, т.е., число 3154h.
3) Регистровый – данное содержится в определённом командой регистре, т.е., в адресном поле команды указывается адрес регистра.
Примеры: mov ax, cx
Регистровую адресацию легко отличить от всех остальных по тому признаку, что все операнды команд являются регистрами. Такие команды являются наиболее компактными и выполняются быстрее других типов команд, поскольку отсутствуют обращения к памяти.
4) Регистровый косвенный – является частным случаем косвенной адресации, когда адрес, указываемый в команде, является указателем ячейки, содержащей смещение операнда в памяти (Рисунок 5.3).
Фактически в команде указывается адрес адреса, причём в качестве регистра адреса может выступать базовый регистр BP или индексные регистры SI или DI .
Косвенная адресация является более эффективной, чем прямая, поскольку в адресном поле команды указывается только адрес регистра, который короче полного адреса операнда в памяти. Однако при этом режиме адресации требуется предварительная загрузка регистра косвенным адресом памяти, на что расходуется дополнительное время.
Примеры: mov ax,
Если в регистре si содержится 10, то в регистр ax будет помещено значение, находящееся по смещению 10 в сегменте данных.
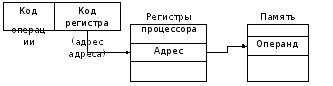
Рисунок 5.3 – Косвенная адресация
Косвенную адресацию удобно использовать при решении задач, когда оставляя неизменным адрес регистра в команде, можно изменять содержимое ячейки с этим адресом.
5) Регистровый относительный – является обобщением методов адресации, обеспечивающих вычисление эффективного адреса (EA ) операнда в памяти в виде суммы базового значения адреса и «смещения» disp, указываемого в команде (Рисунок 5.4) и (Формула 5.1).

Рисунок 5.4 – Формирование эффективного адреса при
относительной адресации
 (5.1)
(5.1)
Относительную адресацию широко применяют как для адресации памяти, представленной в виде блоков (например, сегментов), так и для адресации специальных структур данных: массивов, записей и др. В зависимости от способа использования адресуемого в команде регистра, различают базовый и индексный режимы адресации.
5.1) Индексный – применяется для обработки упорядоченных массивов данных, каждое из которых определяется собственным номером. Тогда базовый адрес массива задаётся смещением disp, указываемым в команде, а значение индекса (номер элемента массива) определяется содержимым индексного регистра (Формула 5.2).
 (5.2)
(5.2)
Пример: d_s segment
mas db 3,5,1,8,9,’$’
assume ds:d_s, cs:c_s
mov si,0 ;в si-номер элемента массива
m1:mov ah, mas ;mas- смещение
;в ah – значение элемента массива mas с
;номером в si
Индексная адресация удобна, если необходимо записать или считать список данных из последовательных ячеек памяти не подряд, а с некоторым шагом, указанным в индексе.
5.2) Базовый – применяется для доступа к структурам данных переменной длины. Тогда базовый адрес, определяющий начало набора элементов, хранится в базовом регистре, а смещение в команде определяет расстояние до определённого элемента (Формула 5.3).
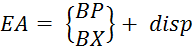 (5.3)
(5.3)
Этот режим адресации удобно использовать для записей – структур данных, содержащих поля различной длины и возможно различных типов.
Рассмотрим пример организации записи о сотрудниках некоторого отдела и доступа к ней и её полям. Условимся, что все поля символьные.
worker struc ;информация о сотруднике
nam db 30 dup (" ") ;фамилия, имя, отчество
position db 30 dup (" ") ;должность
age db 2 dup(‘ ’) ;возраст
standing db 2 dup(‘ ’) ;стаж
salary db 5 dup(‘ ’) ;оклад в рублях
;описание одного сотрудника
sotr1 worker <‘Иванов Пётр Сергеевич’,
‘программист’, ‘30’, ‘8’, ‘15000’>
assume ds:d_s, cs:c_s
;загружаем в bx адрес начала записи (базовый адрес)
lea bx , sotr 1
;в ax – значение по адресу bx+смещение по полю age
;т.е., от начала записи находим ячейки,
mov ax , word ptr [ bx ]. age
В записях с полями различной длины содержимое адресуемого регистра соответствует началу записи, а смещение в команде – расстоянию в записи.
Способы адресации данных. Регистровый, базовый индексный, относительный базовый индексный режимы адресации.
6) Базово- индексный – используется для доступа к элементам массива, адресуемого указателем. Базовый адрес массива задаётся указателем базы (базовым регистром), а номер элемента массива – содержимым индексного регистра (Формула 5.4).
 (5.4)
(5.4)
Пример: mov ax, bx
Если в bx содержится 100, а в si находится 52, то по адресу (смещению) 152 в сегменте данных находится искомое данное.
Такой режим адресации удобно использовать при работе со сложными структурами данных, поскольку позволяет изменять две адресные компоненты.
7) Относительный базовый индексный – используется для адресации элементов в указываемом массиве записей. Базовый адрес массива задаётся указателем базы, номер записи (т.е., элемента массива) определяется содержимым индексного регистра, а смещение в команде указывает расстояние до записи (Формула 5.5).
 (5.5)
(5.5)
;опишем массив из 5 сотрудников со значениями по
;умолчанию
mas_sotr worker 5 dup (<>)
assume ds:d_s, cs:c_s
;в bx – адрес начала массива сотрудников
lea bx , mas _ sotr
;в si – смещение второй записи
mov si , ( type worker )*2
; в ax – стаж второго сотрудника
mov ax,.standing
Таким образом, чтобы получить доступ к конкретному полю массива записей, сначала необходимо определить начало массива, в нём найти нужную запись, а уже в ней – требуемое поле.
Выбор режима адресации определяется конкретной задачей и во многих случаях очевиден. Однако возникают ситуации, когда для обращения к одним и тем же элементам данных допускается использование нескольких способов адресации. В конечном итоге, при написании программы сам пользователь осуществляет выбор конкретного режима адресации.
Способы адресации команд.
В зависимости от того, в каком сегменте кода находится требуемая команда и явно или нет указывается её адрес, выделяют следующие режимы адресации команд:
1) Внутрисегментный прямой – эффективный адрес перехода вычисляется как сумма текущего содержимого указателя команд IP и 8- или 16- битного относительного смещения. Данный режим допустим в условных и безусловных переходах. Например,
Если содержимое регистров ah и al не равны (команда jne ), то осуществляется переход к команде с меткой met .
2) Межсегментный прямой – в команде указывается пара: сегмент и смещение. Сегмент загружается в сегментный регистр CS, а смещение - в регистр IP. Данный режим допусти только в командах безусловного перехода. Например, call far ptr quickSort (вызов процедуры quickSort, расположенной в другом сегменте кода).
Таким образом, при прямой адресации в адресном поле команды содержится адрес перехода – адрес, по которому размещается следующая выполняемая команда.
3) Внутрисегментный косвенный – смещение адреса перехода есть содержимое регистра или ячейки памяти, указанные в любом режиме адресации данных, кроме непосредственного. Содержимое указателя команд IP заменяется соответствующим содержимым регистра или ячейки памяти. Данный способ допустим только в командах безусловного перехода. Например, jmp (перейти на команду, адрес которой находится в ячейке по адресу, указанному в регистре bx ).
4) Межсегментный косвенный – содержимое регистров CS и IP заменяется содержимым двух смежных слов памяти, адрес которых указан в любом режиме адресации данных, кроме непосредственного и регистрового. Младшее слово загружается в регистр IP, старшее – в регистр CS. Данный режим допустим только в командах безусловного перехода. Например, call far ptr (вызов процедуры, расположенной по адресу, указанном в регистре BP плюс ещё 4 байта).
Рассмотренные способы адресации команд используются практически во всех системах команд, расширяя или сокращая список команд конкретного микропроцессора.
Как
уже отмечалось ранее, одной из важных
характеристик любого процессора является
разрядность его внутренних регистров,
а также внешних шин адресов и данных.
Например, процессор Intel
8086 имеет 16-разрядную архитектуру и такой
же разрядности шину данных. Таким
образом, максимальное число, с которым
может работать процессор, составляет
![]() .
Однако адресная шина процессора Intel
8086 содержит 20 линий, что соответствует
адресному пространству
Мбайт. Для получения 20-разрядного
физического адреса ячейки памяти
требуется сложить начальный адрес
сегмента памяти, в котором располагается
эта ячейка, и смещение этой ячейки
относительно начала сегмента (Рисунок
5.5).
.
Однако адресная шина процессора Intel
8086 содержит 20 линий, что соответствует
адресному пространству
Мбайт. Для получения 20-разрядного
физического адреса ячейки памяти
требуется сложить начальный адрес
сегмента памяти, в котором располагается
эта ячейка, и смещение этой ячейки
относительно начала сегмента (Рисунок
5.5).

Рисунок 5.5 – Формирование физического адреса ячейки памяти
Сегментный адрес без 4 младших битов (т.е., делённый на 16), хранится в одном из сегментных регистров (SS, DS, CS, ES).
При вычислении физического адреса процессор умножает содержимое сегментного регистра на 16 и добавляет к полученному 20-разрядному адресу смещение.
Современные 32-разрядные процессоры имеют 32-разрядную адресную шину, что соответствует адресному пространству Гбайта. Однако описанный выше способ формирования физического адреса не позволяет выйти за пределы 1 Мбайта. Для преодоления этого ограничения в 32-разрядных процессорах используются два режима работы: реальный и защищённый. В реальном режиме процессор функционирует фактически также, как Intel 8086 с повышенным быстродействием и может обращаться только к 1 Мбайту адресного пространства. Оставшаяся память, даже если она установлена на компьютере, использоваться не может. В защищённом режиме также используются сегменты и смещения, но физические начальные адреса сегментов извлекаются из таблиц сегментных дескрипторов, индексируемых с помощью тех же сегментных регистров. Каждый сегментный дескриптор занимает 8 байт, из которых 4 байта (32 бита) отводятся под сегментный адрес. Такой механизм позволяет обеспечить полное использование 32-разрядного адресного пространства. В 64-разрядных процессорах также применяется сегментная организация памяти и может использоваться сегментно-страничная /1/ организация памяти; под физический адрес отводится 40, 44, 48, 64 разряда. Таким образом, объём адресного пространства в 64-разрядных микропроцессорах может составлять от 1Тбайта (1 терабайт - байт) до нескольких Эбайтов (1 эксабайт - байт).
В предыдущих главах упоминалось о том, что процессор, с одной стороны, координирует функционирование отдельных устройств вычислительной машины, с другой,- сам выполняет вычисления в соответствии с программой пользователя (принцип программного управления). Далее рассмотрим, каким образом осуществляется выполнение команд процессором и его взаимодействие с другими устройствами.
Передача управления. Переходы и процедуры.
Согласно /8/, поток управления – это последовательность, в которой команды выполняются динамически (во время выполнения программы). Большинство команд не меняют поток управления: после выполнения одной команды выполняется команда, расположенная следом за ней в памяти. Счётчик команд (IP) после выполнения каждой команды увеличивается на число, соответствующее длине команды. Изменение потока управления происходит при наличии команд переходов (условных и безусловного), вызова процедур, сопрограмм, а также при возникновении исключений и прерываний.
1) Команды перехода . При выполнении команд перехода в счётчик команд IP принудительно записывается новое значение – новый адрес в памяти, начиная с которого будут выполняться команды.
Команда безусловного перехода обеспечивает переход по заданному адресу без проверки каких-либо условий. Например, jmp met, означает переход к команде, которая начинается с адреса met в тексте программы. При этом все предшествующие ей команды пропускаются.
Условный переход (ветвление) происходит только при соблюдении определённого условия, в противном случае выполняется следующая по порядку команда программы. Условием, на основании которого осуществляется переход, чаще всего выступают признаки результата выполнения предшествующей арифметической или логической команды. Каждый из признаков фиксируется в своём разряде регистра флагов PSW. Возможен и такой подход, когда решение о переходе принимается в зависимости от состояния одного из регистров общего назначения, куда предварительно помещается результат операции сравнения /3/. Рассмотрим примеры:
|
jz m1 m1: add al,2 |
cmp ah,al je m1 m1: add al,2 |
Левый фрагмент иллюстрирует проверку содержимого регистров AH и AL на равенство, используя флаги, в частности флаг нуля ZF. Предварительно выполняется вычитание содержимого регистров: если их значения равны, то в результате образуется ноль и изменяется значение флага ZF. Команда JZ проверяет, если флаг ZF равен 1, то выполняется переход на команду с адресом M1(add al,2), иначе выполняется команда сложения add ah,3. Команда с адресом M2 выполняется в любом случае. Правый фрагмент выполняет ту же проверку, но с использованием команды сравнения (cmp ah,al) и команды перехода по равенству (je m1).
2) Процедуры . Согласно /3,8/, важным способом структурирования программ является процедура. Она может быть вызвана в любой точке программы. Но в отличие от команд перехода после выполнения процедуры управление возвращается к команде, следующей за командой вызова процедуры.
Процедурный механизм базируется на командах вызова процедуры, обеспечивающих переход из текущей точки программы к начальной команде процедуры, и командах возврата из процедуры, для возврата в точку, непосредственно расположенную за командой вызова. Для работы с процедурами используется стек (дополнительная память, организованная в виде очереди), в который команда вызова помещает текущее значение счётчика команд (IP) при внутрисегментных переходах (или значения регистров IP и CS при межсегментных переходах) – адрес точки возврата. При выходе из процедуры старые значения соответствующих регистров восстанавливаются из стека. Процедура ограничивается операторами PROC и ENDP.
Особый интерес представляет рекурсивная процедура – процедура, которая вызывает сама себя либо непосредственно, либо через цепочку других процедур. Для таких процедур также используется стек, в котором помимо адреса возврата сохраняются параметры и локальные переменные для каждого вызова.
Рассмотрим в качестве примера программу, использующую вызов процедуры. Поскольку процедура расположена в том же сегменте кода, что и основная программа и описана как процедура ближнего вызова (директива NEAR), то переход будет внутрисегментным.
s_s segment stack "stack"
assume ss:s_s,ds:d_s,cs:c_s
call pr 1 ;вызов подпрограммы
mov ah ,4 ch
pr 1 proc near ;начало подпрограммы (ближний вызов)
push ax ;записать в стек содержимое регистра AX
pop ax ;выбрать из стека содержимое регистра AX
ret ;команда возврата на следующую команду после
;вызова процедуры
pr 1 endp ;конец подпрограммы
При выполнении вызова процедуры PR1 (команда call pr1) в стек помещается адрес возврата – содержимое счётчика команд IP, содержащего на данный момент адрес команды, которая должна будет выполняться после текущей (mov ah,4ch). Значение регистра IP замещается новым значением – адресом первой команды процедуры. При достижении команды возврата из процедуры (ret) из стека в регистр IP записывается старое значение, что обеспечивает возврат в основную программу на команду mov ah,4ch, которая непосредственно следует за командой вызова процедуры.
Взаимодействие вызывающей и вызываемой процедур иллюстрирует рисунок 5.6 /8/.
Передача управления. Сопрограммы. Исключения и прерывания
Сопрограммы . В обычной последовательности вызовов существует чёткое различие между вызываемой процедурой и вызывающей процедурой. Вызываемая процедура при каждый раз начинается сначала, сколько бы раз к ней не происходило обращение. Для выхода из вызываемой процедуры используется команда возврата RET, как описано в предыдущем пункте. Пусть имеются две процедуры A и B, каждая из которых вызывает другую в качестве процедуры. При возврате из B к A процедура B совершает переход к тому оператору, следующему за командой вызова процедуры B. Когда процедура A передаёт управление процедуре B, она возвращается не к самому началу B (за исключением первого раза), а к тому месту, где произошёл предыдущий вызов A. Процедуры, работающие подобным образом, называются сопрограммами .

Рисунок 5.6 – Взаимодействие вызывающей и вызываемой
процедур
Обычно сопрограммы используются для того, чтобы производить параллельную обработку данных на одном процессоре. Обычные команды CALL и RET не подходят для вызова сопрограмм, поскольку адрес для перехода берётся из стека, как и при возврате, но, в отличие от возврата, при вызове сопрограммы адрес возврата помещается в определённом месте, чтобы в последующем к нему вернуться. Для этого сначала необходимо вытолкнуть старый адрес возврата из стека и поместить его во внутренний регистр, затем поместить счётчик команд IP в стек и, наконец, скопировать содержимое внутреннего регистра в счётчик команд. Поскольку одно слово выталкивается из стека, а другое помещается в стек, состояние указателя стека не меняется. Схема взаимодействия сопрограмм показана на рисунке 5.7 /8/.

Рисунок 5.7 – Взаимодействие сопрограмм
4) Исключения и прерывания обеспечивают принудительную передачу управления специальной процедуре - обработчику системных прерываний , который выполняет определённые действия. После завершения действий обработчик прерывания возвращает управление прерванной программе. Она должна продолжить выполнение прерванного процесса в том же самом состоянии, в котором находилась в момент прерывания. Обработчик прерываний отличается от обычной процедуры тем, что вместо связывания с конкретной программой, он размещается в фиксированной области памяти.
Исключение - это особый тип вызова процедуры, который происходит при определённом условии – важном, но редко встречающемся. Наиболее распространенные условия, которые могут вызвать исключения,- переполнение и исчезновение значащих разрядов при операциях с плавающей точкой, переполнение при операциях с целыми числами, нарушение защиты, неопределяемый код операции, переполнение стека, попытка запустить несуществующее УВВ, попытка вызвать слово из ячейки с нечётным адресом, деление на ноль. Если результат находится в пределах допустимого, исключение не возникает. Важно отметить, что этот вид прерывания вызывается каким-то исключительным условием, вызванным самой программой и обнаруженным аппаратным обеспечением или микропрограммой. Исключения, в свою очередь, подразделяются на сбои , ловушки и аварийные завершения .
Сбой – это исключение, сообщение о котором выдаётся на границе команды, предшествующей команде, вызвавшей это исключение. После сообщения о сбое состояние вычислительной машины восстанавливается в ситуацию, когда можно выполнить рестарт команды. Примером сбоя может служить обращение к несуществующему УВВ.
Ловушка – это исключение, сообщение о котором выдаётся на границе команды, непосредственно расположенной после команды, для которой было обнаружено данное исключение. Например, переполнение при обработке целых чисел.
Аварийное завершение – это исключение, не позволяющее ни точно определить команду, вызвавшую его, ни перезапустить программу, в которой произошло данное исключение. Аварийные завершения используются для сообщения о серьёзных ошибках: аппаратных ошибках, противоречивых или недопустимых значениях в системных таблицах.
Прерывания - это изменения в потоке управления, вызванные не самой программой, а какими-то асинхронными событиями, и связанные обычно с процессом ввода-вывода. Прерывания дают возможность осуществлять операции ввода-вывода независимо от процессора. Поскольку быстродействие микропроцессора выше, чем УВВ, то процессор имеет возможность выполнять другие программы или осуществлять другие функции вместо постоянного контроля состояния присоединённых к нему периферийных устройств. Когда УВВ требует обслуживания со стороны процессора, оно сообщает ему об этом путём формирования соответствующего запроса (сигнала), по которому процессором может быть прервано выполнение текущей программы. Управление прерываниями от УВВ осуществляется контроллером прерываний, который подключён к процессору и структурно входит в его состав.
Различие между исключениями и прерываниями заключается в том, что исключения синхронны по отношению к программе, а прерывания асинхронны. Исключения вызываются программой непосредственно, а прерывания - опосредованно. Если многократно перезапускать программу с одними и теми же входными данными, то исключения будут возникать всякий раз в одних и тех же местах программы, а прерывания - нет.
Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы, процессор может иметь систему защиты от прерываний: отключение системы прерываний, запрет или маскирование отдельных сигналов прерываний. Программное управление этими средствами позволяет операционной системе регулировать обработку сигналов прерываний. Процессор может обрабатывать прерывания сразу по их приходу, откладывать их обработку на некоторое время, полностью игнорировать. Например, если установлен в единицу флажок трассировки TF, то процессор выполняет одну команду программы, а затем генерирует прерывание типа 1, т.е., программа выполняется по шагам. Если сброшен флаг прерываний IF, то процессор не реагирует на внешние прерывания (за исключением немаскируемых). Для маскирования отдельных видов прерываний используется регистр масок. Управляется командами CLI (запретить прерывания) и STI (разрешить прерывания).
С каждым отдельным типом прерывания или исключением связан идентифицирующий его номер в диапазоне от 0 до 255 и соответствующий обработчик. Исключениям и немаскируемым прерываниям присвоены номера из интервала от 0 до 31, а маскируемым прерываниям – от 32 до 255. Не все из этих значений используются процессорами в настоящее время; неназначенные номера зарезервированы для использования в будущем. Номера прерываний, исключений и адреса (векторы) соответствующих обработчиков хранятся в специальной таблице – таблице векторов прерываний , расположенной в памяти. При возникновении прерывания или исключения по его номеру в таблице векторов прерываний определяется адрес соответствующей процедуры обработки прерывания или исключения, к которой осуществляется переход. Рассмотрим более подробно, каким образом выполняется вызов и возврат из обработчика прерываний или исключений.
Механизмы обработки прерываний и исключений во многом схожи, но есть некоторые отличия, связанные с возвратом из обработчика. Механизм обработки прерываний включает в себя следующие этапы:
1) Установление факта прерывания.
2) Запоминание в стеке состояния прерванного процесса, которое определяется содержимым регистра флагов PSW, счётчика команд IP, сегментного регистра CS. При необходимости, также запоминается содержимое регистров, которые будут использоваться процедурой прерывания и, следовательно, изменяться. Некоторые типы исключений и прерываний также помещают в стек код ошибки для того, чтобы диагностировать причину, вызвавшую исключение.
3) Определение адреса процедуры обработки прерывания по номеру прерывания в таблице векторов прерываний и осуществление перехода к этому обработчику путём загрузки адреса в регистры CS и IP.
4) Обработка прерывания. Процедура обработки прерывания выполняет свои команды.
5) Восстановление состояния прерванной программы. После успешного выполнения процедуры обработки прерывания при достижении команды IRET (этой командой завершаются обработчики прерываний) из стека восстанавливается старое содержимое сохраненных в нём регистров (старое состояние), в т.ч., и адрес возврата – значения регистров CS и IP.
6) Возврат в прерванную программу. На основании адреса возврата осуществляется переход к прерванному процессу. Возврат должен осуществляться на команду, следующей за командой, выполненной до возникновения прерывания. Процедура обработки прерываний, обладающая таким свойством, называется прозрачной .
При возникновении сбоя адрес возврата является адресом команды, вызвавшей сбой, поэтому возврат осуществляется снова к этой команде для попытки повторного её выполнения (рестарта). Обработка ловушек аналогична обработке прерываний. При аварийных завершениях вычислительный процесс завершается без возможности восстановления исходного состояния программы, в которой произошло данное исключение.
Поскольку сигналы прерываний возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерываний, которые могут быть обработаны только последовательно. Для этого прерываниям присваиваются приоритеты. Существуют две дисциплины обслуживания приоритетных прерываний: 1) прерывание с более высоким приоритетом может прервать обработку прерывания с более низким приоритетом и 2) прерывание с более низким приоритетом обслуживается до конца, после чего обрабатывается прерывание с более высоким приоритетом.
В следующей главе рассмотрим вопросы, касающиеся организацией памяти ВМ.
Архитектурные особенности процессоров Pentium.
В соответствии с /2/, микропроцессор Pentium (1993 год) является первым суперскалярным процессором для персональных компьютеров. Включает в себя следующие функциональные блоки:
1) блок ШИ;
2) два 5-ступенчатых конвейера (U и V) выполнения команд целочисленных вычислений;
3) раздельные кэши команд и данных уровня L1 объёмом 8 Кбайт каждый;
4) блок вычислений с плавающей FPU точкой, организованный в виде конвейера;
5) блок предсказания ветвлений;
6) блок управления памятью.
Большинство команд выполняется за один такт. В случае выполнения сложных команд используется расширенный микрокод из ПЗУ микропрограмм сложных команд.
Конвейеры Pentium реализуют традиционные 5 этапов выполнения команд (выборку, декодирование операции, чтение операндов, записи результатов). При вычислении операций с плавающей точкой добавляются ещё три шага: X1 – преобразование данных в формате расширенной сложности, X2 - выполнение FPU-команды, WF – округление результата и его запись в регистровый файл FPU. Конвейер U может выполнять как целочисленные команды, так и команды с плавающей точкой. При этом команды арифметики с плавающей точкой не могут запускаться в паре с целочисленными командами. Кроме того, конвейер U содержит многоразрядный сдвигатель, используемый при выполнении арифметических, логических, циклических сдвигов, операций умножения и деления. Конвейер V выполняет только целочисленные команды.
Использование независимых кэшей обеспечивает одновременный бесконфликтный доступ к ним. Кэш-память команд связана с буфером предварительной выборки 256-битовой шиной. Если выбираемая команда в кэш-памяти отсутствует, то выполняется чтение искомой команды из основной памяти и её загрузка в буфер предвыборки с одновременной записью в кэш команд.
Кэш-память данных соединяется с конвейерами U и V при помощи двух 32-разрядных шин, что обеспечивает возможность одновременного обращения к ней со стороны каждого конвейера.
Блок управления памятью осуществляет двухступенчатое формирование физического адреса ячейки памяти сначала в пределах сегмента, а потом в пределах страницы. Для управления работой внешнего кэша используются специальные аппаратные средства.
Архитектурным нововведением Pentium является специальный режим системного управления (SMM – System Management Mode), который разработан для перевода системы в состояние пониженного энергопотребления. Этот режим не доступен приложениям и управляется программой из ПЗУ на кристалле процессора. В режиме SMM Pentium использует иное, изолированное от других режимов пространство памяти.
Блок ШИ обеспечивает связь процессора с другими устройствами через системную шину, включающую в себя 64-разрядную шину данных и 32-разрядную шину адреса и шину управления. Процессор Pentium поддерживает работу систем с физической памятью до 4 Гбайт.
Развитие процессоров Pentium связано, прежде всего, с совершенствованием технологии их производства, расширением системы команд, совершенствованием алгоритмов предсказания переходов, методов загрузки конвейеров, способов взаимодействия с кэш-памятью.
Отличительной особенностью процессоров Pentium 6-го (Pentium Pro, Pentium II, Pentium III) и 7-го (Pentium IV) поколений от ранних моделей Pentium является иной подход к реализации принципа многооперационной обработки данных. Он заключается в том, что вместо увеличения числа конвейеров исполнения команд, что требует значительных аппаратных затрат, используется один конвейер с большим количеством исполнительных блоков. Например, обработка команд в Pentium IV осуществляется 20-ступенчатым конвейером (гиперконвейером), который условно можно разделить на 3 относительно независимых конвейера:
1) Входной конвейер упорядоченной обработки, который обеспечивает выборку команд из памяти, декодирование их во внутренние RISC-команды и устранение ложных взаимосвязей по данным и ресурсам.
2) Конвейер неупорядоченной обработки, который реализует собственно исполнение команд. При неупорядоченной обработке более интенсивная загрузка конвейеров суперскалярного процессора. Чтобы гарантировать правильное исполнение программы, результаты команд, выполненных вне очереди, должны записываться по целевым адресам в том же порядке, в каком они следуют в исходной программе. Эту работу осуществляет специальный блок процессора – блок временного хранения результатов, выполненных вне очереди.
3) Конвейер вывода результатов исполнения команд, который осуществляет запись результатов в архитектурные регистры процессора и память в порядке, предусмотренном программой.
Эффективная работа гиперконвейера Pentium IV также обеспечивается за счёт спекулятивного исполнения команд, когда для непрерывной загрузки конвейера выполняются действия, не предусмотренные программным кодом.
В блоке предсказания ветвлений используется более совершенный, по сравнению с более ранними моделями процессоров Pentium, алгоритм предсказания ветвлений. Адреса команд переходов и метки ветвлений с подробной предысторией сохраняются в буфере (объёмом 4 Кбайта) блока предсказания ветвлений.
Ещё одним важным отличием процессора Pentium IV от ранних моделей является использование в его структуре вместо кэша команд кэша трасс. Трассы – это последовательности микрокоманд, в которые декодированы команды x86, принадлежащие одной или нескольким ветвям исходной программы. В кэше могут размещаться до 12 Кбайт микрокоманд. В кэш трасс не попадают команды, которые никогда не будут использоваться. Кэш трасс совместно с блоком выборки образуют устройство предварительной обработки.
Использование гиперконвейера, кэша трасс и более производительного исполнительного ядра позволило достигнуть в Pentium IV существенного повышения производительности.
Программная модель процессоров Pentium.
Объединяющей характеристикой рассмотренных микропроцессоров Pentium является то, что все они, несмотря на существенные различия в архитектуре, имеют одинаковую программную модель. Совокупность всех программно доступных регистров процессора образует его программную модель /2/. Она показывает те ресурсы процессора, которыми может пользоваться программист.
Программная модель подразделяется на прикладную и системную. В состав прикладной программной модели (ППМ) процессора входят полный набор регистров, которые доступны прикладным программистам; особенности организации памяти и доступные способы адресации; типы данных и команд. Системная программная модель (СПМ) процессора объединяет его программно доступные системные ресурсы, с помощью которых обеспечивается доступ к встроенным механизмам защиты и многозадачности. СПМ процессора в основном используется системными программистами.