Какие разрабатываются новейшие типы процессоров. Типы процессоров
Исходный вариант компьютера IBM PC и модель IBM PC XT использовали микропроцессор Intel-8088. В начале 80-х годов эти микропроцессоры выпускались с тактовой частотой 4,77 МГц, затем были созданы модели с тактовой частотой 8, 10 и 12 МГц. Модели с увеличенной производительностью (тактовой частотой) иногда называются TURBO-XT. Сейчас микропроцессоры типа Intel-8088 производятся в небольших количествах, и для использования не в компьютере, а в различных специализированных устройствах.
Модель IBM PC AT использует более мощный микропроцессор Intel-80286, и ее производительность приблизительно в 4-5 раз больше, чем у IBM PC XT. Исходные варианты IBM PC AT работали на микропроцессорах с тактовой частотой от 12 до 25 МГц, т. е. работающие в 2-3 раза быстрее. Микропроцессор Intel-80286 имеет несколько больше возможностей по сравнению с Intel-8088, но эти дополнительные возможности используются очень редко, так что большинство программ, работающих на AT, будет работать и на XT. Сейчас микропроцессоры типа Intel-80286 также считаются устаревшими и для применения в компьютерах не производятся.
В 1988-1991 гг. большая часть выпускаемых компьютеров была основана на достаточно мощном микропроцессоре Intel-80386, разработанным фирмой Intel в 1985 г. Этот микропроцессор (называемый также 80386DX) работает в 2 раза быстрее, чем работал бы 80286 с той же тактовой частотой. Обычный диапазон тактовой частоты 80386DX - от 25 до 40 МГц. Кроме того, фирмой Intel был разработан также микропроцессор Intel-80386SX, он ненамного до роже Intel-80286, но обладает теми же возможностями, что и Intel-80386, только при более низком быстро действии (приблизительно в 1, 5-2 раза).
Микропроцессор Intel-80386 не только работает быстрее Intel-80286, но и имеет значительно больше возможностей, в частности, он содержит мощные средства для 32-разрядных операций (в отличие от 16-разрядных 80286 и 8088).
Эти средства активно используются производителями программного обеспечения, поэтому многие выпускаемые сейчас программы предназначены для использования только на компьютерах с микропроцессорами модели Intel-80386 или более старшей.
При создании микропроцессора Intel-80386 фирма Intel рассматривала его как самый передовой микропроцессор, обеспечивающий достаточную производительность для большинства решаемых задач. Однако получившая широчайшее распространение начиная с 1990-1991 гг. операционная оболочка Windows фирмы Microsoft резко увеличила требования к вычислительным ресурсам компьютера, и во многих случаях работа Windows-программ на компьютере с микропроцессором Intel-80386 оказалась слишком медленной. Поэтому в течение 1991-1992 гг. большинство производителей компьютеров переориентировались на использование более мощного микро процессора Intel-80486 (или 80486DX). Этот микропроцессор мало отличается от Intel-80386, но его производительность в 2-3 раза выше. Среди его особенностей следует отметить встроенную кэш-память и встроенный математический сопроцессор. Фирмой Intel также разработаны более дешевый, но менее производительный вариант -80486SX и более дорогие и более быстрые варианты -80486DX2 и DX4. Тактовая частота 80486 обычно находится в диапазоне 25-50 МГц, 80486DX2- 50-60 МГц, а DX4- до 100 МГц.
В 1993 г. фирмой Intel был выпущен новый микропроцессор Pentium (ранее анонсировавшийся под названием 80586). Этот микропроцессор еще более мощен, особенно при вычислениях над вещественными числами. Как и Intel-80486, он содержит встроенный математический сопроцессор, причем значительно более эффективный, чем у Intel-80486. Для увеличения производительности в Pentium применены и другие усовершенствования: более быстрая и более широкая магистраль передачи данных (шина данных), большой размер встроенной кэш-памяти, возможность выполнения двух инструкций одно временно и т. д. Тактовая частота выпускаемых микропроцессоров Pentium- от 60 до 233 МГц. При этом микропроцессоры Pentium работают в 1, 5-2 раза быстрее микропроцессоров типа 80486 с той же тактовой частотой, а для задач, требующих интенсивных вычислений над вещественными числами -в 3-4 раза быстрее.
В конце 1996 - начале 1997 годов Intel выпустила улучшенный процессор Pentium ММХ (MMX - Multimedia Extension). Хотя внешне он мало отличается от своего предшественника, архитектура команд претерпела сильные изменения. В наборе инструкций микросхемы появилось 57 новых. Они предназначены для выполнения задач, связанных с обработкой аудио-, видео-, графических и телекоммуникационных данных.
Чтобы разместить в корпусе существующего Pentium новые возможности, компании пришлось пойти на некоторые компромиссы, а именно - процессоры с ММХ не могут одновременно выполнять инструкции ММХ и операции с плавающей запятой, так как и для ММХ команд, и для чисел с плавающей запятой используются одни и те же регистры встроенного сопроцессора. А сделано это для сохранения полной совместимости Pentium ММХ с существующим программным обеспечением. Это не такая уж большая проблема, поскольку сопроцессор используют немногие программы. Однако если найдутся приложения, требующие от процессора частого переключения между операциями с плавающей запятой и ММХ, они будут выполняться на ММХ - процессоре медленнее, чем на обычном процессоре с той же тактовой частотой.
Корпорация Intel 7 мая 1997 года официально представила процессор Pentium II. Выпускаются варианты процессора с тактовой частотой 233 Мгц и 300 МГц, рассчитанные на питание 2.8 В. Главной новостью стало то, что Pentium II не совместим с существующими материнскими платами для Pentium. Новый процессор будет монтироваться в S.E.C-картридже (Single Edge Contact). Полностью закрытый корпус картриджа защищает компоненты, теплоотводящая пластина позволяет использовать любые радиаторы для пассивного или активного теплоотвода. Благодаря этому тепловыделение для модели с тактовой частотой 233 МГц не превышает 38.2 Вт (для сравнения: Pentium 200МГц выделяет 37.9 Вт). Картридж S.E.C будет вставляться в разъем Slot 1, предложенный Intel в качестве нового технологического стандарта форм-фактора компоновки компьютера.
В январе 1999 г. корпорация Intel официально представила свой микропроцессор для PC Pentium III. По словам представителя компании Сета Уолкера, Pentium III должен продвинуть технологию вперед сразу на нескольких фронтах, включая тактовую частоту (первые модели процессора будут работать на частоте 450 и 500 МГц), обработку графики, скорость и надежность работы с Интернетом. План дальнейшего развития семейства изделий Pentium III предусматривает переход с технологической нормы 0,25 мкм на 0,18 мкм (рабочее название соответствующего микропроцессора - Coppermine). Переход с 0,25 мкм на 0,18 мкм приведет к повышению его производительности и снижению потребляемой мощности. Это позволит довести быстродействие кристаллов до 600 МГц и выше. Тактовая частота первых 0,25-мкм процессоров Pentium III составит 450 и 500 МГц. В процессор добавлены новые инструкции. Этот набор команд с кодовым названием Katmai New Instructions нацелен на повышение производительности обработки графики. Кроме того, он поможет ускорить работу приложений видео, аудио, распознавания речи и других подобных технологий. В марте 2001 г. Intel выпустила процессор Xeon 900 МГц - он стал последним членом семейства Pentium III. Этот процессор оснащен 2-Мбайт кэшем второго уровня, что повышает его производительность.
В ноября 2000 г. корпорация Intel подтвердила свое намерение выпустить микропроцессор Pentium 4 и объявила об планах перевода массовых настольных PC с Pentium III на Pentium 4 уже к концу 2001 года. Процессор Pentium 4 построен на основе микроархитектуры Intel NetBurst. Это первая принципиально новая микроархитектура процессоров для настольных ПК, разработанная фирмой за последние пять лет, с тех пор как в 1995 году был выпущен процессор Pentium Pro с микроархитектурой P6. В архитектуре NetBurst используется несколько новых технологий: гиперконвейерная технология (Hyper Pipelined Technology) с глубиной конвейера, вдвое превышающей таковую в Pentium III; ядро быстрого выполнения (Rapid Execution Engine), повышающее производительность при работе с целочисленными данными за счет работы на удвоенной тактовой частоте по сравнению с частотой основного ядра; и кэш-память с отслеживанием выполнения (Execution Trace Cache), хранящая уже «декодированные» команды; таким образом устраняется задержка при анализе повторно исполняемых участков кода.
Процессор Pentium 4 содержит 42 млн транзисторов на кристалле, снабжен кэш-памятью объемом 256 Кбайт и имеет 144 новые инструкции - так называемые потоковые SIMD-расширения-2 (SSE2), ускоряющие обработку блоков данных с плавающей запятой. В качестве основы платформ на базе Pentium 4 применяется чипсет Intel 850. Это пока единственный набор микросхем на рынке, разработанный для нового процессора. Чипсет поддерживает двухканальную память Rambus Direct RAM (RDRAM) с пропускной способностью 1,6 Гбайт/с по каждому каналу и системную шину с тактовой частотой 400 МГц и пропускной способностью до 3,2 Гбайт/с. На самом деле тактовая частота системной шины равна 100 МГц, а за один такт выполняется четыре операции (аналогичное решение применяется в AGP 4x). Intel также представила первую системную плату ATX D850GB для настольных ПК на базе нового чипсета. В настоящее время выпускаются 1.4-, 1.5- и 1.7-ГГц версии Pentium 4. Они производятся по 0,18-микронной технологии.
По мнению ведущих аналитиков, в 2001 году производители микрочипов произведут переход 2-ГГц рубежа: новые технологии производства полупроводниковых микросхем, включая нанесение на полимерную пленку и сверхминиатюризацию, позволят производителям перейти рубеж в 2 ГГц.
Структура микропроцессора.
Микропроцессор-это полупроводниковое устройство, состоящее из одной или нескольких программно-управляемых БИС, включающих все средства, необходимые для обработки информации и управления, и рассчитанное на совместную работу с устройствами памяти и ввода-вывода информации.
Микропроцессор состоит из трех основных блоков:
Арифметически-логического
Блока регистров
Устройства управления
Арифметически-логическое устройство (АЛУ) - выполняет все арифметические и логические преобразования данных.
Устройство управления - электронный блок компьютера, включающий в работу устройства, блоки, электронные элементы и цепи в зависимости от содержания текущей команды.
Регистр - ячейка памяти в виде совокупности триггеров, предназначенных для хранения одного данного в двоичном коде.
Количество разрядов в регистре определяется разрядностью микропроцессора
Регистры общего назначения - образуют сверхоперативную и служат для хранения операндов участвующих в вычислениях, а также результатов вычислений.
Операндом называются - исходные данные, над которыми производятся различные действия в арифметическом устройстве.
Регистр команд - служит для хранения команды, выполняемой в текущий момент времени.
Счетчик команд - регистр, указывающий адрес ячейки памяти, где хранится следующая команда.
Стек (стековая память) - совокупность связанных между собой регистров для хранения упорядоченных данных. Первый выбирается из стека данное попавшее туда последним, и наоборот.
Процессор выполняет следующие функции:
1) вычисление адресов команд и операндов;
2) выборку и дешифрацию команд из оперативной памяти;
3) выборку данных из оперативной памяти, микропроцессорной памяти и регистров адаптеров внешних устройств;
4) приём и обработку запросов и команд от внешних устройств;
5) обработку данных и их запись в оперативную память, регистры микропроцессора и регистры адаптеров внешних устройств;
6) выработку управляющих сигналов для всех прочих узлов и блоков компьютера;
7) переход к следующей команде.
Согласно /4/, основными параметрами микропроцессоров являются: разрядность , рабочая тактовая частота , размер кэш-памяти , состав инструкций , конструктив.
1) Разрядность внутренних регистров – количество бит, которые процессор способен обработать за один приём. Разрядность шины данных определяет количество разрядов, над которыми одновременно могут выполняться операции. Разрядность шины адреса определяет объём памяти (адресное пространство), с которым может работать процессор. Адресное пространство – это максимальное количество ячеек памяти, которое может быть непосредственно адресовано микропроцессором.
2) Рабочая тактовая частота (МГц) во многом определяет быстродействие процессора, поскольку каждая команда выполняется за определённое число тактов. Чем короче машинный такт, тем выше производительность процессора. Быстродействие компьютера также зависит и от тактовой частоты шины системной платы, с которой работает процессор.
3) Кэш-память , устанавливаемая на плате микропроцессора, имеет два уровня:
3.1) L 1 – память первого уровня, находящаяся внутри основной микросхемы (ядра) процессора и работающая всегда на полной частоте процессора (впервые появилась в микропроцессорах Intel 386SLC и 486).
3.2) L 2 – память второго уровня, кристалл, размещаемый на плате микропроцессора и связанный с ядром внутренней шиной (впервые введена в микропроцессорах Pentium II). Эта память может работать на полной или половинной частоте процессора.
4) Состав инструкций – перечень, вид и тип команд, автоматически выполняемых микропроцессором. Определяет непосредственно те процедуры, которые могут выполняться над данными и те категории данных, над которыми могут выполняться эти процедуры. Существенное изменение состава инструкций произошло в микропроцессорах Intel 80386 (этот состав принят за базовый), Pentium MMX, Pentium III, Pentium 4.
5) Конструктив подразумевает те физические разъёмные соединения, в которые устанавливается микропроцессор. Разные разъёмы имеют различную конструкцию (щелевой разъём – Slot, разъём-гнездо – Soket), разное количество контактов.
Процессоры классифицируются по различным признакам. В соответствии с /4, 13/, можно выделить следующие основные признаки:
1) По назначению микропроцессоры делятся на универсальные и специализированные . Первые предназначены для решения широкого круга задач, в системе команд заложена алгоритмическая универсальность. Таким образом, производительность процессора слабо зависит от специфики решаемых задач. Специализированные процессоры предназначены для решения определённого круга задач или даже одной задачи, имеют ограниченный набор команд. Среди них выделяются процессоры для обработки данных , математические процессоры и микроконтроллеры .
2) По количеству выполняемых программ процессоры подразделяются на однопрограммные (переход к выполнению следующей программы происходит только после завершения текущей программы) и мультипрограммные (одновременно выполняются несколько программ).
3) По структурному признаку выделяют микропроцессоры с фиксированной разрядностью (имеют строго определённую разрядность) и микропроцессоры с наращиваемой разрядностью (позволяют секциями увеличивать число разрядов).
4) По числу БИС (СБИС) в микропроцессорном комплекте можно выделить однокристальные , многокристальные и многокристальные секционные процессоры. В первом случае все аппаратные части процессора реализованы в виде одной БИС (СБИС); возможности таких процессоров ограничены ресурсами кристалла и корпуса. Многокристальные процессоры получаются в результате разбиения логической структуры процессора на функционально законченные части, каждая из которых реализована в виде БИС или СБИС. В последнем случае функционально законченные части логической структуры процессора разбиваются на секции, которые реализованы в виде БИС.
5) По разрядности обрабатываемой информации микропроцессоры могут быть 4, 8, 12, 16, 24, 32 и 64-разрядными. На практике наибольшее распространение имеют 32-разрядные процессоры; всё большее применение находят 64-разрядные процессоры.
6) По виду технологии изготовления БИС (СБИС) микропроцессоры делятся на две группы: процессоры, построенные на БИС, изготовленных по униполярной технологии , и процессоры, построенные на БИС, изготовленных по биполярной технологии . Представители первой группы: p -канальные (p -МОП) , n -канальные (n -МОП) , комплиментарные (КМОП) БИС. (МОП – металл-окисел-проводник). Ко второй группе относятся БИС на базе транзисторно- транзисторной логики (ТТЛ) , эмиттерно-связанной логики (ЭСЛ) и интегральной инжекторной логики (И 2 Л) . Вид технологии изготовления БИС во многом определяет степень интеграции микросхем, быстродействие, энергопотребление, помехозащищённость и стоимость процессоров. По комплексу этих признаков можно отдать предпочтение микропроцессорам, выполненным по n-МОП и КМОП- технологиям, обеспечивающим высокую плотность компоновки, высокое быстродействие и относительно малую стоимость. ЭСЛ обеспечивает самое высокое быстродействие процессоров, но низкую плотность компоновки и высокое энергопотребление. Технология И 2 Л даёт усреднённые характеристики микропроцессоров.
7) По характеру системы команд выделяют процессоры с полным набором инструкций или CISC -процессоры (Complex Instruction Set Command), процессоры с сокращённым набором инструкций или RISC -процессоры (Reduced Insrruction Set Command), процессоры со сверхбольшим командным словом или VLIW -процессоры (Very Long Instruction Word). CISC-процессоры имеют большой набор разноформатных команд, что позволяет применять эффективные алгоритмы решения задач, но, в то же время, усложняет схему процессора, и в общем случае не обеспечивает максимального быстродействия. Архитектура CISC присуща классическим процессорам. RISC-процессоры содержат набор простых, чаще всего встречающихся в программах инструкций. При необходимости выполнения более сложных команд в микропроцессоре производится их автоматическая сборка из простых команд. Все простые команды имеют одинаковый размер и на их выполнение тратится один машинный такт (на выполнение самой короткой команды из системы CISC обычно тратится четыре такта). Современные 64-разрядные RISC-процессоры выпускаются многими фирмами: Apple (PowerPC), IBM (PPC) т.д. В VLIW-процессорах одна инструкция содержит несколько операций, которые должны выполняться параллельно. Задача распределения работы между несколькими вычислительными устройствами процессора решается во время компиляции программы. Такой подход позволили уменьшить габариты процессоров и потребление энергии. Примерами VLIW-процессоров служат Itanium фирмы Intel, McKinley фирмы Hewlett-Packard и другие.
8) По числу и способу использования внутренних регистров различают аккумуляторные , многоаккумуляторные и стековые процессоры. Аккумуляторные процессоры – это процессоры с одним регистром результата. Их отличительной характеристикой является относительная простота аппаратной реализации, а также упрощённый формат команд (будут рассмотрены в следующей лекции). В командах адрес операнда в аккумуляторе не указывается, а адресуется только второй операнд. Недостатками таких процессоров является необходимость предварительной загрузки операнда в аккумулятор перед выполнением операции и невозможность непосредственной записи результата выполнения команды в произвольную ячейку памяти или регистр. В многоаккумуляторных регистрах, которыми являются большинство современных процессоров, функции регистров результата может выполнять любой регистр общего назначения или ячейка памяти. В командах оба операнда задаются явно, а результат операции чаще всего помещается на место одного из операндов. В стековых процессорах обычно используется большой аппаратный стек и дополнительный внешний стек в памяти (при нехватке аппаратного). Благодаря специальному размещению операндов в стеке обработку информации можно выполнять безадресными командами, что позволяет повысить производительность процессора и экономить память. Такие команды извлекают из стека один или два операнда, выполняют над ними соответствующую арифметическую или логическую операцию и заносят результат в вершину стека. Недостатком является необходимость предварительной подготовки данных, использующих адресные команды.
С историей развития процессоров и их сравнительной характеристикой более подробно можно ознакомится в /4, 13/. Далее рассмотрим физическую и функциональную структуру процессора.
Физическая и функциональная организация ЦП (на примере ЦП Intel 8086). ШИ.
Физическая структура процессора является достаточно сложной. В соответствии с /4/, ядро процессора содержит главный управляющий и исполняющие модули – блоки выполнения операций над целочисленными данными. К локальным управляющим схемам относятся: блок с плавающей запятой, модуль предсказания ветвлений, регистры микропроцессорной памяти, регистры кэш-памяти 1-го уровня, шинный интерфейс и многое другое.
Примечание: Под логическим ядром понимается схема, по которой сделан процессор. Физически ядро представляет собой кристалл, на котором с помощью логических элементов реализована принципиальная схема процессора.
В самом общем случае функциональную структуру процессора можно представить в виде композиции, согласно одним источникам /4, 5/, двух частей: операционного устройства (ОУ ) и шинного интерфейса (ШИ ), согласно другим /2/,- трёх блоков: операционного блока (ОБ ), управляющего блока (УБ ) и интерфейсного блока (ИБ ). Имеющиеся незначительные расхождения в количестве и названии блоков никоим образом не нарушают число и принципы функционирования компонентов процессора. Поэтому рассмотрим первый (более наглядный) вариант из источника /4/.
Упрощённая типовая структура процессора представлена на рисунке 4.1.
ОУ содержит устройство управления (УУ), арифметико-логическое устройство (АЛУ), регистр флагов, регистры общего назначения (РОН), регистры-указатели, индексные регистры. ШИ содержит адресные регистры, блок регистров (буфер) команд, узел формирования адреса, схемы управления шиной и портами. Обе части микропроцессора работают параллельно, причём ШИ работает быстрее ОУ. Рассмотрим эти блоки процессора более подробно.
ШИ предназначен для связи и согласования микропроцессора с системной шиной компьютера, а также для приёма, предварительного анализа команд выполняемой программы и формирования полных адресов операндов и команд.
Сегментные (адресные) регистры совместно с узлом формирования адреса реализуют сегментацию памяти. Команды и данные хранятся в ячейках, и их местоположение в памяти определяется адресами соответствующих ячеек. Поскольку команды и данные на уровне кодов неотличимы друг от друга, то для различия команд и данных используется их размещение в различных областях памяти – сегментах. Сегмент - это прямоугольная область памяти, характеризующаяся начальным адресом и длиной. Начальный адрес (адрес начала сегмента) – это номер (адрес) ячейки памяти, с которой начинается сегмент. Длина сегмента – это количество входящих в него ячеек памяти. Сегменты могут иметь различную длину. Все ячейки, расположенные внутри сегмента, перенумеровываются, начиная с нуля. Адресация ячеек внутри сегмента ведется относительно начала сегмента; адрес ячейки в сегменте называется смещением или эффективным адресом - EA (относительно начального адреса сегмента). Текущий сегмент можно указать с помощью загрузки соответствующего сегментного регистра:
1) CS (Code Segment ) – определяет начало текущего сегмента кода, в котором располагаются команды программы. Выборка команды производится с использованием в качестве эффективного адреса содержимого регистра IP (Instruction Pointer ) , а в качестве адреса сегмента – содержимого CS. Именно регистр IP хранит смещение адреса текущей команды программы.
2) DS (Data Segment ) – определяет начало текущего сегмента данных. Ссылки на данные (за некоторым исключением) осуществляются относительно содержимого этого регистра.
3) SS (Stack Segment ) – определяет начало текущего сегмента стека. Как правило, все адреса данных, связанных со стеком, задаются относительно содержимого этого регистра.
4) ES (Extended Segment ) – определяет начало дополнительного текущего сегмента, который обычно рассматривается как вспомогательный сегмент данных (при межсегментных пересылках).
Узел формирования адреса и регистр команд функционально входят в состав УУ и были рассмотрены выше.
При адресации устройств ввода-вывода (УВВ) сегментные регистры не используются. Взаимодействие с ними процессор осуществляет через специальное адресное пространство – порты. Каждый порт имеет номер, что соответствует адресу подключённого к нему устройства. Порту устройства соответствует аппаратура сопряжения и два регистра – для обмена данными и управляющей информацией. Схема управления шиной и портами выполняет следующие функции:
1) формирование адреса порта и управляющей информации для него;
2) приём управляющей информации от порта, информации о готовности порта и его состоянии;
3) организация сквозного канала в системном интерфейсе для передачи данных между портом УВВ и процессором.
Схема управления шиной и портами использует для связи с портами системную шину: шину адреса, шину данных и шину инструкций.
Физическая и функциональная организация ЦП (на примере ЦП Intel 8086). ОУ.
В целом ОУ выполняет операции, определяемые командами, и формирует эффективные адреса.
УУ вырабатывает управляющие сигналы, поступающие во все блоки вычислительной машины. В составе УУ можно выделить следующие функциональные блоки:
1) регистр команд – запоминающий регистр, в котором хранится код команды: код операции и адреса операндов (расположен в интерфейсной части процессора);
2) дешифратор операций – логический блок, который в соответствии с поступающим из регистра команд кодом операции выбирает один из множества имеющихся у него выходов;
3) постоянное запоминающее устройство (ПЗУ) микропрограмм хранит управляющие импульсы для выполнения в блоках вычислительной машины процедур обработки информации; импульс по выбранному дешифратором операций проводу считывает из ПЗУ микропрограмм необходимую последовательность управляющих сигналов;
4) узел формирования адреса (располагается в ШИ) – устройство для вычисления полного адреса ячейки памяти (регистра) по реквизитам, поступающим из микропроцессорной памяти или регистра команд;
5) кодовые шины данных, адреса и инструкций – часть внутренней интерфейсной шины процессора.
Таким образом, УУ формирует управляющие сигналы для выполнения процессором своих функций, рассмотренных выше.
Рисунок 4.1 – Упрощённая типовая структура процессора
АЛУ предназначено для выполнения арифметических и логических операций преобразования информации. Функционально в простейшем варианте АЛУ состоит из следующих компонент:
1) сумматор выполняет процедуру сложения двоичных кодов, имеет разрядность двойного машинного слова (32 бита);
2) регистры – быстродействующие ячейки памяти различной длины: регистр 1 имеет разрядность 32 бита, регистр 2 - 16 бит; при сложении в регистр 1 помещается первое слагаемое, а потом результат, в регистр 2 – второе слагаемое;
3) схема управления принимает по кодовым шинам инструкций управляющие сигналы от УУ и преобразует в сигналы для управления работой регистров и сумматора.
АЛУ выполняет арифметические операции только над двоичными числами с фиксированной точкой. Для обработки чисел с плавающей точкой привлекается математический сопроцессор или специально составленные программы.
Более подробные сведения об устройстве и функционировании УУ и АЛУ можно найти в /3 - 5/.
Регистры ОУ – часть микропроцессорной памяти. Рассмотрим регистры на примере базового процессора Intel 8086, который содержит всего 14 двухбайтовых регистра. В современных процессорах их гораздо больше и большей разрядности. Однако в качестве базовой модели, в частности для языка Ассемблера, используется 14-регистровая память процессора.
В состав ОУ входят следующие регистры:
1) регистры общего назначения (РОН) или универсальные : AX - (AH, AL), BX - (BH, BL), CX - (CH, CL), DX - (DH, DL) могут использоваться для временного хранения любых данных, при этом можно работать с каждым регистром целиком, а можно отдельно, с каждой его половиной; но каждый из РОН может использоваться и как специальный при выполнении некоторых конкретных команд;
2) регистры смещений : SP, BP, SI, DI являются неделимыми и предназначены для хранения относительных адресов ячеек памяти внутри сегментов (смещений относительно начала сегментов);
2.1) SP (Stack Pointer ) – смещение вершины стека;
2.2) BP (Base Pointer ) – смещение начального адреса поля памяти, непосредственно отведённого под стек;
2.3) SI (Source Index ) , DI (Destination Index ) предназначены для хранения адресов индекса источника и приёмника данных при операциях над строками и им подобных.
Слово состояния процессора (PSW – Processor State Word ) или регистр флагов – имеет размер 2 байта и содержит одноразрядные признаки или флаги. Всего в регистре 9 флагов: 6 из них условные или статусные , отражают результаты операций, выполненных ОУ, остальные 3– управляющие , определяют режим исполнения программы.
1) Статусные флаги.
1.1) CF (Carry Flag ) – флаг переноса. Устанавливается в 1, если при выполнении арифметических и некоторых операций сдвига возникает «перенос» из старшего разряда.
1.2) PF (Parity Flag) – флаг чётности. Проверяет младшие 8 битов результатов над данными. Чётное число единиц приводит к установке этого флага в 1, нечётное – в 0.
1.3) AF (Auxiliary Carry Flag ) – флаг логического переноса в двоично-десятичной арифметике. Устанавливается в 1, если арифметическая операция приводит к переносу или займу четвёртого справа бита однобайтового операнда. Используется при арифметических операциях над двоично-десятичными кодами и кодами ASCII.
1.4) ZF (Zero Flag ) – флаг нуля. Устанавливается в 1, если результат операции равен 0, в противном случае ZF обнуляется.
1.5) SF (Sign Flag) – флаг знака. Устанавливается в 1, если результат арифметической операции является отрицательным, в 0, если результат положительный.
1.6) OF (Overflow Flag ) – флаг переполнения. Устанавливается в единицу при арифметическом переполнении, когда результат выходит за пределы разрядной сетки.
2) Управляющие флаги.
2.1) TF (Trap Flag ) – флаг трассировки. Единичное состояние этого флага переводит процессор в режим пошагового выполнения программы.
2.2) IF (Interrupt Flag) – флаг прерываний. При нулевом состоянии этого флага прерывания запрещены, при единичном – разрешены (о механизме прерываний речь пойдёт в следующей лекции).
2.3) DF (Direction Flag ) – флаг направления. Используется в строковых операциях для задания направления обработки данных; при единичном состояния строки обрабатываются «справа налево», при нулевом – «слева направо».
Расположение флагов в регистре PSW показано на рисунке 4.2. Свободные биты отведены для использования в будущем.
Рисунок 4.2 – Схема расположения флагов в регистре PSW
Архитектурные принципы организации RISC-процессоров.
Как отмечается в /2, 14, 15/, список команд современного микропроцессора может содержать достаточно большое число команд. Однако не все они используются одинаково часто и регулярно. Это свойство системы команд явилось предпосылкой для развития процессоров с RISC-архитектурой. Основная идея заключалась в сокращении списка используемых команд и, вследствие этого, упрощение управляющего блока процессора и для организации более быстрого исполнения оставшихся команд за счёт освободившихся при этом ресурсов кристалла.
Первые процессоры с сокращённым набором команд были реализованы в начале 80-х годов 20 века /2/:
1) В 1980 году в калифорнийском университете города Беркли под руководством профессоров Давида Паттерсона (David Patterson) и Карло Секуина (Carlo Sequin) был разработан процессор, который получил название RISC. Были разработаны модели RISC-I, RISC-II, SOLAR.
2) В 1981 году в университете города Стэнфорда под руководством Джона Хеннеси (Dohn Hennesy) был спроектирован процессор, получивший название MIPS (Microprocessor Without Interlocked Pipeline Stages – микропроцессор без блокировки конвейера). Более подробно о сути конвейеризации будет рассмотрено в следующем вопросе лекции.
Позднее обе модели с сокращённым набором команд стали называть RISC-процессорами. Отличительной особенностью этих процессоров является большое количество РОН (порядка 256).
Кратко охарактеризуем основные принципы RISC-архитектуры /2, 15/.
1) Одинаковая длина команд . Это облегчает их выборку из основной памяти. Все команды считываются за один такт, что позволяет обрабатывать поток командных инструкций по конвейерному принципу, то есть выполняется синхронизация аппаратных частей процессора с учётом последовательной передачи управления от одного аппаратного блока к другому. В современных RISC-процессорах длина команды составляет 32 бита.
2) Сокращённый набор действий над операндами, размещёнными в памяти . Простые способы адресации памяти обеспечивают быстрый доступ к операндам в памяти. Обработка данных, реализуемая при выполнении команд RISC, никогда не совмещается с операциями чтения (записи) памяти (в отличие от многих команд CISC). Обмен операндами между памятью и регистрами выполняется специальными командами загрузки (LOAD) и запоминания (STORE). Большое количество регистров блока РОН позволяет уменьшить число обращений к памяти.
3) Выполнение всех вычислительных операций над данными, размещёнными только в РОН. Поскольку регистров много, то все скалярные переменные и даже небольшие массивы переменных чаще всего размещаются в регистрах, что позволяет ускорить обработку данных. Использование простых команд упрощает реализацию их конвейерной обработки. В среднем команды RISC выполняются за один такт.
4) Относительно простые схемы управления . Уменьшение списка команд, использование команд, реализующих только простые операции, исключение в командах обработки данных обращений к памяти позволили уменьшить расход ресурсов кристалла на управление. Благодаря этому большая площадь кристалла выделяется для размещения устройств, позволяющих увеличить общую производительность процессора: дополнительных конвейеров, увеличенной кэш-памяти 1-го уровня, большего числа РОН.
Важно отметить, что при одинаковой технологии производства RISC-процессоры имеют более высокие частоты работы по сравнению с CISC-процессорами, что является важным достоинством RISC-процессоров.
Согласно /15/, в архитектуре RISC-процессоров можно выделить следующие аппаратные блоки, образующие ступени конвейера:
1) Блок загрузки инструкций включает в себя следующие составные части: блок выборки инструкций из памяти, регистр инструкций, куда помещается команда после выборки и блок декодирования инструкций. Эта ступень называется ступенью выборки инструкций.
2) РОН совместно с блоками управления регистрами образуют вторую ступень конвейера, которая отвечает за чтение операндов команд. Операнды могут храниться в самой команде или в одном из РОН. Эта ступень называется ступенью выборки операндов.
3) АЛУ и, если в данной архитектуре реализован аккумулятор, вместе с логикой управления , которая исходя из содержимого регистра инструкций определяет тип выполняемой микрооперации. При выполнении операций условного и безусловного переходов источником данных может быть также счётчик команд. Данная ступень называется исполнительной ступенью конвейера.
4) Набор из РОН и логики записи образуют ступень сохранения данных. Здесь результаты выполнения команд записываются в РОН или основную память.
К RISC-процессорам причисляют микропроцессоры MIPS R4000, R8000, R100000 фирмы MIPS Technologies Inc., UltraSPARC I, UltraSPARC II, UltraSPARC III фирмы Sun, PowerPC фирмы IBM-Motorola, Alpha AXP фирмы DEC, PA-RISC фирмы Hewlett Packard, микроконтроллеры фирмы Microchip.
Несмотря на очевидные преимущества, RISC-процессоры «в чистом виде» не получили широкого распространения на рынке персональных компьютеров, большинство из них используется в качестве центральных процессоров рабочих станций. Однако большинство современных CISC-процессоров, например, Pentium, используют достижения RISC-архитектур, в частности, RISC-ядра для выполнения вычислительных операций.
Модели RISC-процессоров активно развиваются и совершенствуются. В настоящее время на их основе реализуются коммерчески важные продукты: SPARC- и MIPS-системы.
Более полные сведения о RISC-процессорах, особенностях их архитектуры и функционирования можно найти в /2/, специальной литературе и открытых источниках сети Интернет.
Архитектурные способы повышения производительности процессоров. Конвейерная обработка информации.
Производительность является одной из наиболее важных характеристик процессора. Согласно /2/, в общем случае она определяется количеством вычислительной работы, выполняемой в единицу времени. К важнейшим факторам, влияющим на производительность, относятся тактовая частота, число команд программы, среднее время выполнения отдельной команды. Для упрощённой оценки производительности процессора часто используют показатель, указывающий число команд, выполняемых за секунду. Он определяется как частное от деления тактовой частоты на среднее время выполнения процессором отдельной команды и измеряется в MIPS (Meg Insruction Per Second) для целочисленных задач и MFLOPS (Meg Floating Point Operations Per Second) для вычислений с плавающей точкой. При этом оценки показателя, определяющего число команд, выполняемых за секунду, проводят для операций с регистровыми операндами, не привязываясь к быстродействию основной памяти. Однако этот показатель не учитывает особенности архитектуры конкретных процессоров. Поэтому для сравнительных характеристик различных процессоров используются относительные оценки производительности, для получения которых используются специальные тестовые программы.
В соответствии с /2/, повышение производительности процессоров в большинстве случаев достигается за счёт применения специальных технологических и архитектурных решений. Технологические подходы (совершенствование технологий производства ИС, увеличение степени интеграции) были рассмотрены ранее, во второй главе. Поэтому подробнее остановимся на архитектурных способах повышения производительности процессоров. Совершенствование архитектуры процессоров, обеспечивающее повышение его производительности, в настоящее время связано, прежде всего, с развитием средств параллельной обработки данных. Здесь можно выделить следующие направления:
1) Увеличение «естественного» параллелизма – повышение разрядности обработки и передачи данных (разрядность процессоров повысилась с 4 до 32 и 64 разрядов).
2) Конвейерная (многофазная) обработка данных – вычислительный процесс делится на несколько фаз, для каждой из которых используются свои средства и буфер для хранения результата (ступень конвейера).
3) Многоэлементная обработка данных - параллельная обработка данных в нескольких операционных блоках (ОУ) процессора.
Способы параллельной обработки могут сочетаться. Например, в одном процессоре можно организовать несколько операционных блоков, в каждом из которых использовать конвейеризацию.
Рассмотрим более детально два последних направления.
При многофазной обработке, как показано на рисунке 4.3, процесс обработки данных разбивается на несколько стадий (фаз), выполняемых последовательно.
Рисунок 4.3 – Многофазная обработка данных
Между фазами имеются буферы для хранения промежуточных результатов. После выполнения первой фазы результат запоминается в буфере и начинается обработка второй фазы. Средства выполнения первой фазы освобождаются, и на них поступает следующая порция данных. Если длительность фаз обработки одинакова и составляет T / n , то при таком способе производительность системы увеличится в n раз. Этот способ соответствует конвейерной обработке.
Рассмотрим организацию конвейера на уровне исполнения машинной команды /2/. Каждый блок в конвейерной цепочке осуществляет только один этап исполнения команды. Полная обработка команды занимает несколько тактов.
Типовые этапы выполнения команды: 1) выборка команды IF (Instruction Fetch), 2) дешифрация команды ID (Instruction Decode), 3) чтение операндов RD (Read Memory), 4) исполнение заданной в команде операции EX (Execute), 5) запись результата WB (Write Back). В ходе выполнения команда продвигается по конвейеру, освобождая очередную ступень для следующей команды. Содержимое буферов, которые используются для хранения информации, передаваемой по ступеням конвейера, обновляется в каждом такте по завершению этапа исполнения очередной команды. Промежуточные буферы обеспечивают параллельную независимую работу блоков конвейерной цепочки: в то время, когда последующий блок начинает выполнять этап очередной команды, предыдущий блок может приступать к обработке следующей команды, что демонстрирует рисунок 4.4.
|
Такты работы процессора |
||||||||||
|
Команда i | ||||||||||
|
Команда i+1 | ||||||||||
|
Команда i+2 | ||||||||||
|
Команда i+3 | ||||||||||
|
Команда i+4 | ||||||||||
|
Команда i+5 | ||||||||||
Рисунок 4.4 – Конвейерная обработка команд
Следует отметить, что конвейерная обработка команд не уменьшает время выполнения отдельной команды, которое в конвейерном процессоре остаётся таким же, как и в обычном неконвейерном. Однако благодаря тому, что при конвейерной обработке большая часть вычислительного процесса в режиме одновременного выполнения команд, скорость выдачи результатов последовательно выполняемых команд увеличивается пропорционально числу ступеней конвейера. Продолжительность выполнения отдельных этапов исполнения команды в общем случае зависит от типа команды и места размещения операндов. Конвейерная обработка команд наиболее эффективна в том случае, если длительность всех фаз выполнения команды приблизительно одинаковая. К сожалению, обеспечить непрерывную работу конвейера не всегда удаётся из-за различных конфликтов: по ресурсам, по данным, по управлению. Более подробно о конфликтах – в /2, 7/.
Процессор, в котором процесс выполнения команды разбивается на 5-6 ступеней, называется обычным конвейерным процессором . Если увеличить количество ступеней конвейера, то каждая отдельная ступень будет выполнять меньшую работу, а, следовательно, содержать меньше аппаратной логики. Благодаря более коротким задержкам распространения сигналов в каждой отдельно взятой ступени конвейера достигается повышение частоты работы и соответствующее повышение производительности процессора. Процессор, имеющий конвейер существенно глубже 5-6 ступеней, называется суперконвейерным . Например, Pentium II содержит 12 ступеней, UltraSPARC III – 14 ступеней, Pentium 4 – 20 ступеней.
многоэлементная

T и в системе используется n T / n
A = B + C ; D = E + F .
суперскалярным скалярной скалярными
Архитектурные способы повышения производительности процессоров. Многоэлементная обработка информации.
Как показано на рисунке 4.5 /2/, многоэлементная обработка осуществляется на нескольких параллельно работающих ОУ. Каждый элемент выполняет свою работу, осуществляя обработку порции данных от начала до конца.
Рисунок 4.5 – Многоэлементная параллельная обработка данных
Если время выполнения работы на отдельном элементе составляет T и в системе используется n элементов, то при определённой идеализации можно ожидать, что среднее время выполнения такой работы составит T / n (реально - меньше). В современных процессорах такой способ обработки связан с понятием суперскалярной архитектуры.
Простейшим примером вычислительного параллелизма является выполнение двух команд, операнды которых не связаны между собой:
A = B + C ; D = E + F .
Поэтому обе команды можно выполнять одновременно. Для выполнения несвязанных операций в состав процессора включают набор арифметических устройств, каждое из которых обычно имеет конвейерную организацию.
Процессор, содержащий несколько ОУ, которые обеспечивает одновременное выполнение более одной скалярной команды, называется суперскалярным процессором. Команда называется скалярной , если её входные операнды и результат являются числами (скалярами). Традиционные процессоры с одним ОУ называются скалярными . В суперскалярном процессоре обработка команд распараллелена не только во времени (конвейер), но и в пространстве (несколько конвейеров). Производительность такого процессора оценивается темпом схода исполненных команд со всех его конвейеров.
В настоящее время используются два способа суперскалярной обработки. Первый способ базируется на чисто аппаратном механизме выборки несвязанных команд программы из памяти (кэш-памяти, буфера предвыборки) и параллельном запуске их на исполнение. Ответственность за эффективность загрузки параллельно функционирующих конвейеров возлагается на аппаратные средства процессора, что является основным достоинством этого способа суперскалярной обработки. В этом случае процесс трансляции программ для суперскалярного процессора ничем не отличается от трансляции программ для традиционного скалярного процессора. В соответствии с этим способом, сравнительно легко реализуются суперскалярные микропроцессоры различных семейств программно совместимые между собой. При этом не возникает проблем с использованием ранее созданного программного обеспечения. Все процессоры семейства Pentium реализованы по этому способу.
В процессорах, реализующих второй способ суперскалярной обработки, планирование параллельного исполнения нескольких команд возлагается на распараллеливающий компилятор. Сначала он анализирует исходную программу в целях выявления команд, которые могут выполняться одновременно. Затем компилятор группирует такие команды в пакеты команд – длинные командные слова (VLIW), причём, число простых команд в команде VLIW принимается равным числу исполнительных блоков процессора. Поскольку всю работу по подготовке к исполнению VLIW-команд выполняет компилятор, конфликтные ситуации при их исполнении исключаются. Такой способ суперскалярной обработки реализуется в VLIW-процессорах, имеющих статическую сперскалярную архитектуру. К сожалению, для таких процессоров требуется специальное программное обеспечение. Кроме того, программы, скомпилированные для одного поколения микропроцессоров, могут выполняться неэффективно без перекомпиляции на процессорах следующего поколения. Это требует от разработчиков программного обеспечения разработки модифицированных версий исполняемых файлов своего продукта для разных поколений процессоров. Идеи VLIW предложены российскими инженерами и учёными во главе с профессором Б.А. Бабаяном при разработке отечественной супер-ЭВМ «Эльбрус-3» (1990). В настоящее время VLIW-технология реализована в процессоре Эльбрус Е2К отечественной компании «Эльбрус Интернешнл», процессорах Crusoe фирмы Transmeta, а также в семействе сигнальных процессоров (для цифровой обработки сигналов) TMS320C60xx фирмы Texas Instruments.
Классификация и структура команд процессора.
По функциональному признаку все команды процессора можно разделить на следующие группы:
1) команды пересылки данных и ввода-вывода;
2) команды арифметических и поразрядных логических операций;
3) команды передачи управления.
Команды пересылки данных обеспечивают обмен информацией между регистрами микропроцессора, а также внешние обмены данными при передаче в процессор из памяти или устройства ввода и из процессора в память или устройство вывода. В этих командах обычно указывается направление передачи, источник и (или) приёмник данных. Например, в языке Ассемблера, к командам этой группы можно отнести команду пересылки MOV , команду загрузки LOAD , команды записи в порт и чтения из порта УВВ, IN и OUT , соответственно т.п. Также сюда часто включают команды помещения данных в стек PUSH и извлечения данных из стека POP .
В число команд арифметических и поразрядных логических операций в большинстве случаев входят команды простейших арифметических операций, например, ADD (сложить), SUB (вычесть), и логических операций, например, AND («И»), OR («ИЛИ») и т.п. К арифметическим командам также относят команды арифметических и логических сдвигов, а к командам логических операций – команды сравнения COMPARE (неразрушающего вычитания). В число команд этой группы могут входить команды сложных арифметических операций: умножение, деление (есть не во всех процессорах), команды обработки данных с плавающей точкой, команды мультимедийной обработки.
Команды передачи управления используются для изменения последовательности выполнения команд при наличии программных ветвлений: команд условных и безусловного (JMP) переходов, обращении к подпрограммам (CALL) и выхода из них (RETURN). Команды условных переходов реализуют передачи управления в зависимости от значения флагов в регистре PSW. С их помощью процессор одну из возможных ветвей продолжения программы. Обычно в системе команд имеется несколько команд условных переходов.
В современных процессорах системы команд наряду с традиционными командами, перечисленными выше, содержат в своём составе группы команд, расширяющие функциональные возможности микропроцессора по обработке информации, управлению его работой, а также обеспечивающие реализацию многозадачного защищённого режима работы.
В системы команд конкретных процессоров могут входить команды, не вписывающиеся в предложенную классификацию. Подобные команды не отражают общих принципов построения программ и рассматриваются как дополнительные.
Выполнение команды (машинной операции) разделено на более мелкие этапы - микрооперации (микрокоманды), во время которых выполняются определённые элементарные действия. Конкретный состав микроопераций определяется системой команд и логической структурой вычислительной машины. Последовательность микрокоманд, реализующих данную операцию (команду), образует микропрограмму операции. Интервал времени, в течение которого выполняется одна или одновременно несколько микроопераций, называется машинным тактом. Границы тактов задаются синхросигналами, которые вырабатываются генератором синхросигналов.
В общем случае команда микропроцессора содержит две части: операционную и адресную. В соответствии с /1/, соглашение о распределении разрядов между этими частями команды и о способе кодирования информации определяет структуру (формат) команды. В операционной части команды содержится код операции, обеспечивающий кодирование операций (где n – число двоичных разрядов, отведённых под операционную часть команды) и определяющий, какие при этом будут задействованы устройства в процессоре или вне его. В k -разрядной адресной части команды содержится информация об адресах операндов, участвующих в выполнении операции. В общем случае адресная часть команды должна содержать четыре адресных поля A 1 , A 2 , A 3 , A 4 . Они предназначены для задания адресов операндов (A1, A2), адреса результата (A3) и адреса следующей команды (A4). В качестве адресов A1,…,A3 могут использоваться адреса ячеек оперативной памяти и адреса регистров микропроцессорной памяти, в качестве адреса A4- только адреса ячеек оперативной памяти. При использовании полного набора адресов формат команды оказывается громоздким. Было отмечено, что не для всех операций необходим полный набор адресов A1-A4. В зависимости от указываемого числа адресов команды подразделяются на 0-адресные (безадресные) , 1-адресные , 2-адресные , 3-адресные и 4-адресные .
Практически во всех микропроцессорах исключён адрес A4. Это обусловлено тем, что большинство команд относятся к линейным участкам алгоритмов, и такие команды могут быть размещены в ячейках памяти с последовательно возрастающими адресами. В этом случае для получения адреса следующей команды к начальному адресу сегмента кода достаточно добавить её смещение в сегменте кода, что удобно реализовать с помощью указателя команд. Такой способ адресации команд называется естественным , а реализующие его процессоры называются процессорами с естественным способом адресации команд . При нарушении естественного порядка следования команд (ветвлениях, циклах) используются специальные команды передачи управления, в которых содержится адрес перехода, но не используются адреса операндов. Процессоры, в адресном поле команд которых используется адрес A4, называются процессорами с принудительным способом адресации команд .
Использование адреса результата A3 во многих случаях также оказывается избыточным. Это обосновывается тем, что результат арифметических и логических операций над двумя операндами обычно может быть помещён на место одного из операндов, который в дальнейшем, скорее всего, использоваться не будет. При этом в 2-адресных командах в адресное поле необходимо вводить дополнительные разряды, показывающие, кто из них является источником, а кто – приёмником информации. В процессорах с аккумуляторной архитектурой число адресов в адресной части команды уменьшено до одного. В них один из операндов, размещённых в аккумуляторе, неявно задаётся кодом команды, и результат помещается в аккумулятор.
В безадресных командах осуществляется неявное задание операнда. К таким командам относятся команды управления процессором (например, пуска, останова и т.д.), команды для работы со стеком (операнд, адресуемый указателем SP, неявно задаётся кодом команды). Безадресные команды имеют предельно сокращённый формат, но не могут самостоятельно образовать функционально полную систему команд и применяются только вместе с адресными.
Формат команд влияет на время решения задач, затраты памяти, сложность процессора и зависит от класса решаемых задач. В частности, для научно- технических расчётов, в которых большой объём занимают многошаговые вычисления, более эффективными оказываются 1-адресные команды, а при использовании стекового процессора – и безадресные команды. Для задач управления, где большую долю составляют пересылки и логические операции эффективными являются 2-адресные команды. Исходя из сказанного выше, следует отметить, что в современных процессорах обычно используются безадресные, 1-адресные и 2-адресные команды. 3-адресные команды используются крайне редко, а 4-адресные не используются совсем.
Вследствие разнообразия форматов команд и данных (числа, символы, структуры и т.д.), а также их местоположения сформировались различные способы адресации команд и операндов, которые рассмотрим ниже.
Способы адресации данных. Непосредственный, прямой, косвенный, регистровый относительный режимы адресации.
Способы адресации данных определяют механизмы вычисления эффективных адресов операндов в памяти и доступа к операндам. Выделяют следующие способы (режимы) адресации /2, 6/:
1) Непосредственный – позволяет задавать фиксированные значения операнда непосредственно в адресной части команды, т.е., данное является частью команды (Рисунок 5.1). Такой режим адресации удобен при работе с константами.
Рисунок 5.1 – Непосредственная адресация
Примеры: mov ax, 5564h
add al, 1101001100b
Следует помнить, что непосредственный операнд может быть задан только как операнд-источник. Недостатком непосредственной адресации является необходимость расширения формата команд за счёт указания самого операнда в адресном поле команды.
2) Прямой – адрес операнда содержится в коде команды (Рисунок 5.2). Используется при работе с переменными и константами, местоположение которых в памяти не меняется в процессе выполнения задачи.
![]()
Рисунок 5.2 – Прямая адресация
Таким образом, в коде команды указывается смещение операнда в памяти.
Пример: d_s segment
assume ds:d_s, cs:c_s
mov ax , mm ;по адресу mm пересылается 3154h
После выполнения третьей команды в регистре ax будет записано значение по адресу mm в памяти, т.е., число 3154h.
3) Регистровый – данное содержится в определённом командой регистре, т.е., в адресном поле команды указывается адрес регистра.
Примеры: mov ax, cx
Регистровую адресацию легко отличить от всех остальных по тому признаку, что все операнды команд являются регистрами. Такие команды являются наиболее компактными и выполняются быстрее других типов команд, поскольку отсутствуют обращения к памяти.
4) Регистровый косвенный – является частным случаем косвенной адресации, когда адрес, указываемый в команде, является указателем ячейки, содержащей смещение операнда в памяти (Рисунок 5.3).
Фактически в команде указывается адрес адреса, причём в качестве регистра адреса может выступать базовый регистр BP или индексные регистры SI или DI .
Косвенная адресация является более эффективной, чем прямая, поскольку в адресном поле команды указывается только адрес регистра, который короче полного адреса операнда в памяти. Однако при этом режиме адресации требуется предварительная загрузка регистра косвенным адресом памяти, на что расходуется дополнительное время.
Примеры: mov ax,
Если в регистре si содержится 10, то в регистр ax будет помещено значение, находящееся по смещению 10 в сегменте данных.
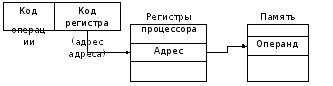
Рисунок 5.3 – Косвенная адресация
Косвенную адресацию удобно использовать при решении задач, когда оставляя неизменным адрес регистра в команде, можно изменять содержимое ячейки с этим адресом.
5) Регистровый относительный – является обобщением методов адресации, обеспечивающих вычисление эффективного адреса (EA ) операнда в памяти в виде суммы базового значения адреса и «смещения» disp, указываемого в команде (Рисунок 5.4) и (Формула 5.1).

Рисунок 5.4 – Формирование эффективного адреса при
относительной адресации
 (5.1)
(5.1)
Относительную адресацию широко применяют как для адресации памяти, представленной в виде блоков (например, сегментов), так и для адресации специальных структур данных: массивов, записей и др. В зависимости от способа использования адресуемого в команде регистра, различают базовый и индексный режимы адресации.
5.1) Индексный – применяется для обработки упорядоченных массивов данных, каждое из которых определяется собственным номером. Тогда базовый адрес массива задаётся смещением disp, указываемым в команде, а значение индекса (номер элемента массива) определяется содержимым индексного регистра (Формула 5.2).
 (5.2)
(5.2)
Пример: d_s segment
mas db 3,5,1,8,9,’$’
assume ds:d_s, cs:c_s
mov si,0 ;в si-номер элемента массива
m1:mov ah, mas ;mas- смещение
;в ah – значение элемента массива mas с
;номером в si
Индексная адресация удобна, если необходимо записать или считать список данных из последовательных ячеек памяти не подряд, а с некоторым шагом, указанным в индексе.
5.2) Базовый – применяется для доступа к структурам данных переменной длины. Тогда базовый адрес, определяющий начало набора элементов, хранится в базовом регистре, а смещение в команде определяет расстояние до определённого элемента (Формула 5.3).
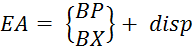 (5.3)
(5.3)
Этот режим адресации удобно использовать для записей – структур данных, содержащих поля различной длины и возможно различных типов.
Рассмотрим пример организации записи о сотрудниках некоторого отдела и доступа к ней и её полям. Условимся, что все поля символьные.
worker struc ;информация о сотруднике
nam db 30 dup (" ") ;фамилия, имя, отчество
position db 30 dup (" ") ;должность
age db 2 dup(‘ ’) ;возраст
standing db 2 dup(‘ ’) ;стаж
salary db 5 dup(‘ ’) ;оклад в рублях
;описание одного сотрудника
sotr1 worker <‘Иванов Пётр Сергеевич’,
‘программист’, ‘30’, ‘8’, ‘15000’>
assume ds:d_s, cs:c_s
;загружаем в bx адрес начала записи (базовый адрес)
lea bx , sotr 1
;в ax – значение по адресу bx+смещение по полю age
;т.е., от начала записи находим ячейки,
mov ax , word ptr [ bx ]. age
В записях с полями различной длины содержимое адресуемого регистра соответствует началу записи, а смещение в команде – расстоянию в записи.
Способы адресации данных. Регистровый, базовый индексный, относительный базовый индексный режимы адресации.
6) Базово- индексный – используется для доступа к элементам массива, адресуемого указателем. Базовый адрес массива задаётся указателем базы (базовым регистром), а номер элемента массива – содержимым индексного регистра (Формула 5.4).
 (5.4)
(5.4)
Пример: mov ax, bx
Если в bx содержится 100, а в si находится 52, то по адресу (смещению) 152 в сегменте данных находится искомое данное.
Такой режим адресации удобно использовать при работе со сложными структурами данных, поскольку позволяет изменять две адресные компоненты.
7) Относительный базовый индексный – используется для адресации элементов в указываемом массиве записей. Базовый адрес массива задаётся указателем базы, номер записи (т.е., элемента массива) определяется содержимым индексного регистра, а смещение в команде указывает расстояние до записи (Формула 5.5).
 (5.5)
(5.5)
;опишем массив из 5 сотрудников со значениями по
;умолчанию
mas_sotr worker 5 dup (<>)
assume ds:d_s, cs:c_s
;в bx – адрес начала массива сотрудников
lea bx , mas _ sotr
;в si – смещение второй записи
mov si , ( type worker )*2
; в ax – стаж второго сотрудника
mov ax,.standing
Таким образом, чтобы получить доступ к конкретному полю массива записей, сначала необходимо определить начало массива, в нём найти нужную запись, а уже в ней – требуемое поле.
Выбор режима адресации определяется конкретной задачей и во многих случаях очевиден. Однако возникают ситуации, когда для обращения к одним и тем же элементам данных допускается использование нескольких способов адресации. В конечном итоге, при написании программы сам пользователь осуществляет выбор конкретного режима адресации.
Способы адресации команд.
В зависимости от того, в каком сегменте кода находится требуемая команда и явно или нет указывается её адрес, выделяют следующие режимы адресации команд:
1) Внутрисегментный прямой – эффективный адрес перехода вычисляется как сумма текущего содержимого указателя команд IP и 8- или 16- битного относительного смещения. Данный режим допустим в условных и безусловных переходах. Например,
Если содержимое регистров ah и al не равны (команда jne ), то осуществляется переход к команде с меткой met .
2) Межсегментный прямой – в команде указывается пара: сегмент и смещение. Сегмент загружается в сегментный регистр CS, а смещение - в регистр IP. Данный режим допусти только в командах безусловного перехода. Например, call far ptr quickSort (вызов процедуры quickSort, расположенной в другом сегменте кода).
Таким образом, при прямой адресации в адресном поле команды содержится адрес перехода – адрес, по которому размещается следующая выполняемая команда.
3) Внутрисегментный косвенный – смещение адреса перехода есть содержимое регистра или ячейки памяти, указанные в любом режиме адресации данных, кроме непосредственного. Содержимое указателя команд IP заменяется соответствующим содержимым регистра или ячейки памяти. Данный способ допустим только в командах безусловного перехода. Например, jmp (перейти на команду, адрес которой находится в ячейке по адресу, указанному в регистре bx ).
4) Межсегментный косвенный – содержимое регистров CS и IP заменяется содержимым двух смежных слов памяти, адрес которых указан в любом режиме адресации данных, кроме непосредственного и регистрового. Младшее слово загружается в регистр IP, старшее – в регистр CS. Данный режим допустим только в командах безусловного перехода. Например, call far ptr (вызов процедуры, расположенной по адресу, указанном в регистре BP плюс ещё 4 байта).
Рассмотренные способы адресации команд используются практически во всех системах команд, расширяя или сокращая список команд конкретного микропроцессора.
Как
уже отмечалось ранее, одной из важных
характеристик любого процессора является
разрядность его внутренних регистров,
а также внешних шин адресов и данных.
Например, процессор Intel
8086 имеет 16-разрядную архитектуру и такой
же разрядности шину данных. Таким
образом, максимальное число, с которым
может работать процессор, составляет
![]() .
Однако адресная шина процессора Intel
8086 содержит 20 линий, что соответствует
адресному пространству
Мбайт. Для получения 20-разрядного
физического адреса ячейки памяти
требуется сложить начальный адрес
сегмента памяти, в котором располагается
эта ячейка, и смещение этой ячейки
относительно начала сегмента (Рисунок
5.5).
.
Однако адресная шина процессора Intel
8086 содержит 20 линий, что соответствует
адресному пространству
Мбайт. Для получения 20-разрядного
физического адреса ячейки памяти
требуется сложить начальный адрес
сегмента памяти, в котором располагается
эта ячейка, и смещение этой ячейки
относительно начала сегмента (Рисунок
5.5).

Рисунок 5.5 – Формирование физического адреса ячейки памяти
Сегментный адрес без 4 младших битов (т.е., делённый на 16), хранится в одном из сегментных регистров (SS, DS, CS, ES).
При вычислении физического адреса процессор умножает содержимое сегментного регистра на 16 и добавляет к полученному 20-разрядному адресу смещение.
Современные 32-разрядные процессоры имеют 32-разрядную адресную шину, что соответствует адресному пространству Гбайта. Однако описанный выше способ формирования физического адреса не позволяет выйти за пределы 1 Мбайта. Для преодоления этого ограничения в 32-разрядных процессорах используются два режима работы: реальный и защищённый. В реальном режиме процессор функционирует фактически также, как Intel 8086 с повышенным быстродействием и может обращаться только к 1 Мбайту адресного пространства. Оставшаяся память, даже если она установлена на компьютере, использоваться не может. В защищённом режиме также используются сегменты и смещения, но физические начальные адреса сегментов извлекаются из таблиц сегментных дескрипторов, индексируемых с помощью тех же сегментных регистров. Каждый сегментный дескриптор занимает 8 байт, из которых 4 байта (32 бита) отводятся под сегментный адрес. Такой механизм позволяет обеспечить полное использование 32-разрядного адресного пространства. В 64-разрядных процессорах также применяется сегментная организация памяти и может использоваться сегментно-страничная /1/ организация памяти; под физический адрес отводится 40, 44, 48, 64 разряда. Таким образом, объём адресного пространства в 64-разрядных микропроцессорах может составлять от 1Тбайта (1 терабайт - байт) до нескольких Эбайтов (1 эксабайт - байт).
В предыдущих главах упоминалось о том, что процессор, с одной стороны, координирует функционирование отдельных устройств вычислительной машины, с другой,- сам выполняет вычисления в соответствии с программой пользователя (принцип программного управления). Далее рассмотрим, каким образом осуществляется выполнение команд процессором и его взаимодействие с другими устройствами.
Передача управления. Переходы и процедуры.
Согласно /8/, поток управления – это последовательность, в которой команды выполняются динамически (во время выполнения программы). Большинство команд не меняют поток управления: после выполнения одной команды выполняется команда, расположенная следом за ней в памяти. Счётчик команд (IP) после выполнения каждой команды увеличивается на число, соответствующее длине команды. Изменение потока управления происходит при наличии команд переходов (условных и безусловного), вызова процедур, сопрограмм, а также при возникновении исключений и прерываний.
1) Команды перехода . При выполнении команд перехода в счётчик команд IP принудительно записывается новое значение – новый адрес в памяти, начиная с которого будут выполняться команды.
Команда безусловного перехода обеспечивает переход по заданному адресу без проверки каких-либо условий. Например, jmp met, означает переход к команде, которая начинается с адреса met в тексте программы. При этом все предшествующие ей команды пропускаются.
Условный переход (ветвление) происходит только при соблюдении определённого условия, в противном случае выполняется следующая по порядку команда программы. Условием, на основании которого осуществляется переход, чаще всего выступают признаки результата выполнения предшествующей арифметической или логической команды. Каждый из признаков фиксируется в своём разряде регистра флагов PSW. Возможен и такой подход, когда решение о переходе принимается в зависимости от состояния одного из регистров общего назначения, куда предварительно помещается результат операции сравнения /3/. Рассмотрим примеры:
|
jz m1 m1: add al,2 |
cmp ah,al je m1 m1: add al,2 |
Левый фрагмент иллюстрирует проверку содержимого регистров AH и AL на равенство, используя флаги, в частности флаг нуля ZF. Предварительно выполняется вычитание содержимого регистров: если их значения равны, то в результате образуется ноль и изменяется значение флага ZF. Команда JZ проверяет, если флаг ZF равен 1, то выполняется переход на команду с адресом M1(add al,2), иначе выполняется команда сложения add ah,3. Команда с адресом M2 выполняется в любом случае. Правый фрагмент выполняет ту же проверку, но с использованием команды сравнения (cmp ah,al) и команды перехода по равенству (je m1).
2) Процедуры . Согласно /3,8/, важным способом структурирования программ является процедура. Она может быть вызвана в любой точке программы. Но в отличие от команд перехода после выполнения процедуры управление возвращается к команде, следующей за командой вызова процедуры.
Процедурный механизм базируется на командах вызова процедуры, обеспечивающих переход из текущей точки программы к начальной команде процедуры, и командах возврата из процедуры, для возврата в точку, непосредственно расположенную за командой вызова. Для работы с процедурами используется стек (дополнительная память, организованная в виде очереди), в который команда вызова помещает текущее значение счётчика команд (IP) при внутрисегментных переходах (или значения регистров IP и CS при межсегментных переходах) – адрес точки возврата. При выходе из процедуры старые значения соответствующих регистров восстанавливаются из стека. Процедура ограничивается операторами PROC и ENDP.
Особый интерес представляет рекурсивная процедура – процедура, которая вызывает сама себя либо непосредственно, либо через цепочку других процедур. Для таких процедур также используется стек, в котором помимо адреса возврата сохраняются параметры и локальные переменные для каждого вызова.
Рассмотрим в качестве примера программу, использующую вызов процедуры. Поскольку процедура расположена в том же сегменте кода, что и основная программа и описана как процедура ближнего вызова (директива NEAR), то переход будет внутрисегментным.
s_s segment stack "stack"
assume ss:s_s,ds:d_s,cs:c_s
call pr 1 ;вызов подпрограммы
mov ah ,4 ch
pr 1 proc near ;начало подпрограммы (ближний вызов)
push ax ;записать в стек содержимое регистра AX
pop ax ;выбрать из стека содержимое регистра AX
ret ;команда возврата на следующую команду после
;вызова процедуры
pr 1 endp ;конец подпрограммы
При выполнении вызова процедуры PR1 (команда call pr1) в стек помещается адрес возврата – содержимое счётчика команд IP, содержащего на данный момент адрес команды, которая должна будет выполняться после текущей (mov ah,4ch). Значение регистра IP замещается новым значением – адресом первой команды процедуры. При достижении команды возврата из процедуры (ret) из стека в регистр IP записывается старое значение, что обеспечивает возврат в основную программу на команду mov ah,4ch, которая непосредственно следует за командой вызова процедуры.
Взаимодействие вызывающей и вызываемой процедур иллюстрирует рисунок 5.6 /8/.
Передача управления. Сопрограммы. Исключения и прерывания
Сопрограммы . В обычной последовательности вызовов существует чёткое различие между вызываемой процедурой и вызывающей процедурой. Вызываемая процедура при каждый раз начинается сначала, сколько бы раз к ней не происходило обращение. Для выхода из вызываемой процедуры используется команда возврата RET, как описано в предыдущем пункте. Пусть имеются две процедуры A и B, каждая из которых вызывает другую в качестве процедуры. При возврате из B к A процедура B совершает переход к тому оператору, следующему за командой вызова процедуры B. Когда процедура A передаёт управление процедуре B, она возвращается не к самому началу B (за исключением первого раза), а к тому месту, где произошёл предыдущий вызов A. Процедуры, работающие подобным образом, называются сопрограммами .

Рисунок 5.6 – Взаимодействие вызывающей и вызываемой
процедур
Обычно сопрограммы используются для того, чтобы производить параллельную обработку данных на одном процессоре. Обычные команды CALL и RET не подходят для вызова сопрограмм, поскольку адрес для перехода берётся из стека, как и при возврате, но, в отличие от возврата, при вызове сопрограммы адрес возврата помещается в определённом месте, чтобы в последующем к нему вернуться. Для этого сначала необходимо вытолкнуть старый адрес возврата из стека и поместить его во внутренний регистр, затем поместить счётчик команд IP в стек и, наконец, скопировать содержимое внутреннего регистра в счётчик команд. Поскольку одно слово выталкивается из стека, а другое помещается в стек, состояние указателя стека не меняется. Схема взаимодействия сопрограмм показана на рисунке 5.7 /8/.

Рисунок 5.7 – Взаимодействие сопрограмм
4) Исключения и прерывания обеспечивают принудительную передачу управления специальной процедуре - обработчику системных прерываний , который выполняет определённые действия. После завершения действий обработчик прерывания возвращает управление прерванной программе. Она должна продолжить выполнение прерванного процесса в том же самом состоянии, в котором находилась в момент прерывания. Обработчик прерываний отличается от обычной процедуры тем, что вместо связывания с конкретной программой, он размещается в фиксированной области памяти.
Исключение - это особый тип вызова процедуры, который происходит при определённом условии – важном, но редко встречающемся. Наиболее распространенные условия, которые могут вызвать исключения,- переполнение и исчезновение значащих разрядов при операциях с плавающей точкой, переполнение при операциях с целыми числами, нарушение защиты, неопределяемый код операции, переполнение стека, попытка запустить несуществующее УВВ, попытка вызвать слово из ячейки с нечётным адресом, деление на ноль. Если результат находится в пределах допустимого, исключение не возникает. Важно отметить, что этот вид прерывания вызывается каким-то исключительным условием, вызванным самой программой и обнаруженным аппаратным обеспечением или микропрограммой. Исключения, в свою очередь, подразделяются на сбои , ловушки и аварийные завершения .
Сбой – это исключение, сообщение о котором выдаётся на границе команды, предшествующей команде, вызвавшей это исключение. После сообщения о сбое состояние вычислительной машины восстанавливается в ситуацию, когда можно выполнить рестарт команды. Примером сбоя может служить обращение к несуществующему УВВ.
Ловушка – это исключение, сообщение о котором выдаётся на границе команды, непосредственно расположенной после команды, для которой было обнаружено данное исключение. Например, переполнение при обработке целых чисел.
Аварийное завершение – это исключение, не позволяющее ни точно определить команду, вызвавшую его, ни перезапустить программу, в которой произошло данное исключение. Аварийные завершения используются для сообщения о серьёзных ошибках: аппаратных ошибках, противоречивых или недопустимых значениях в системных таблицах.
Прерывания - это изменения в потоке управления, вызванные не самой программой, а какими-то асинхронными событиями, и связанные обычно с процессом ввода-вывода. Прерывания дают возможность осуществлять операции ввода-вывода независимо от процессора. Поскольку быстродействие микропроцессора выше, чем УВВ, то процессор имеет возможность выполнять другие программы или осуществлять другие функции вместо постоянного контроля состояния присоединённых к нему периферийных устройств. Когда УВВ требует обслуживания со стороны процессора, оно сообщает ему об этом путём формирования соответствующего запроса (сигнала), по которому процессором может быть прервано выполнение текущей программы. Управление прерываниями от УВВ осуществляется контроллером прерываний, который подключён к процессору и структурно входит в его состав.
Различие между исключениями и прерываниями заключается в том, что исключения синхронны по отношению к программе, а прерывания асинхронны. Исключения вызываются программой непосредственно, а прерывания - опосредованно. Если многократно перезапускать программу с одними и теми же входными данными, то исключения будут возникать всякий раз в одних и тех же местах программы, а прерывания - нет.
Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы, процессор может иметь систему защиты от прерываний: отключение системы прерываний, запрет или маскирование отдельных сигналов прерываний. Программное управление этими средствами позволяет операционной системе регулировать обработку сигналов прерываний. Процессор может обрабатывать прерывания сразу по их приходу, откладывать их обработку на некоторое время, полностью игнорировать. Например, если установлен в единицу флажок трассировки TF, то процессор выполняет одну команду программы, а затем генерирует прерывание типа 1, т.е., программа выполняется по шагам. Если сброшен флаг прерываний IF, то процессор не реагирует на внешние прерывания (за исключением немаскируемых). Для маскирования отдельных видов прерываний используется регистр масок. Управляется командами CLI (запретить прерывания) и STI (разрешить прерывания).
С каждым отдельным типом прерывания или исключением связан идентифицирующий его номер в диапазоне от 0 до 255 и соответствующий обработчик. Исключениям и немаскируемым прерываниям присвоены номера из интервала от 0 до 31, а маскируемым прерываниям – от 32 до 255. Не все из этих значений используются процессорами в настоящее время; неназначенные номера зарезервированы для использования в будущем. Номера прерываний, исключений и адреса (векторы) соответствующих обработчиков хранятся в специальной таблице – таблице векторов прерываний , расположенной в памяти. При возникновении прерывания или исключения по его номеру в таблице векторов прерываний определяется адрес соответствующей процедуры обработки прерывания или исключения, к которой осуществляется переход. Рассмотрим более подробно, каким образом выполняется вызов и возврат из обработчика прерываний или исключений.
Механизмы обработки прерываний и исключений во многом схожи, но есть некоторые отличия, связанные с возвратом из обработчика. Механизм обработки прерываний включает в себя следующие этапы:
1) Установление факта прерывания.
2) Запоминание в стеке состояния прерванного процесса, которое определяется содержимым регистра флагов PSW, счётчика команд IP, сегментного регистра CS. При необходимости, также запоминается содержимое регистров, которые будут использоваться процедурой прерывания и, следовательно, изменяться. Некоторые типы исключений и прерываний также помещают в стек код ошибки для того, чтобы диагностировать причину, вызвавшую исключение.
3) Определение адреса процедуры обработки прерывания по номеру прерывания в таблице векторов прерываний и осуществление перехода к этому обработчику путём загрузки адреса в регистры CS и IP.
4) Обработка прерывания. Процедура обработки прерывания выполняет свои команды.
5) Восстановление состояния прерванной программы. После успешного выполнения процедуры обработки прерывания при достижении команды IRET (этой командой завершаются обработчики прерываний) из стека восстанавливается старое содержимое сохраненных в нём регистров (старое состояние), в т.ч., и адрес возврата – значения регистров CS и IP.
6) Возврат в прерванную программу. На основании адреса возврата осуществляется переход к прерванному процессу. Возврат должен осуществляться на команду, следующей за командой, выполненной до возникновения прерывания. Процедура обработки прерываний, обладающая таким свойством, называется прозрачной .
При возникновении сбоя адрес возврата является адресом команды, вызвавшей сбой, поэтому возврат осуществляется снова к этой команде для попытки повторного её выполнения (рестарта). Обработка ловушек аналогична обработке прерываний. При аварийных завершениях вычислительный процесс завершается без возможности восстановления исходного состояния программы, в которой произошло данное исключение.
Поскольку сигналы прерываний возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерываний, которые могут быть обработаны только последовательно. Для этого прерываниям присваиваются приоритеты. Существуют две дисциплины обслуживания приоритетных прерываний: 1) прерывание с более высоким приоритетом может прервать обработку прерывания с более низким приоритетом и 2) прерывание с более низким приоритетом обслуживается до конца, после чего обрабатывается прерывание с более высоким приоритетом.
В следующей главе рассмотрим вопросы, касающиеся организацией памяти ВМ.
Архитектурные особенности процессоров Pentium.
В соответствии с /2/, микропроцессор Pentium (1993 год) является первым суперскалярным процессором для персональных компьютеров. Включает в себя следующие функциональные блоки:
1) блок ШИ;
2) два 5-ступенчатых конвейера (U и V) выполнения команд целочисленных вычислений;
3) раздельные кэши команд и данных уровня L1 объёмом 8 Кбайт каждый;
4) блок вычислений с плавающей FPU точкой, организованный в виде конвейера;
5) блок предсказания ветвлений;
6) блок управления памятью.
Большинство команд выполняется за один такт. В случае выполнения сложных команд используется расширенный микрокод из ПЗУ микропрограмм сложных команд.
Конвейеры Pentium реализуют традиционные 5 этапов выполнения команд (выборку, декодирование операции, чтение операндов, записи результатов). При вычислении операций с плавающей точкой добавляются ещё три шага: X1 – преобразование данных в формате расширенной сложности, X2 - выполнение FPU-команды, WF – округление результата и его запись в регистровый файл FPU. Конвейер U может выполнять как целочисленные команды, так и команды с плавающей точкой. При этом команды арифметики с плавающей точкой не могут запускаться в паре с целочисленными командами. Кроме того, конвейер U содержит многоразрядный сдвигатель, используемый при выполнении арифметических, логических, циклических сдвигов, операций умножения и деления. Конвейер V выполняет только целочисленные команды.
Использование независимых кэшей обеспечивает одновременный бесконфликтный доступ к ним. Кэш-память команд связана с буфером предварительной выборки 256-битовой шиной. Если выбираемая команда в кэш-памяти отсутствует, то выполняется чтение искомой команды из основной памяти и её загрузка в буфер предвыборки с одновременной записью в кэш команд.
Кэш-память данных соединяется с конвейерами U и V при помощи двух 32-разрядных шин, что обеспечивает возможность одновременного обращения к ней со стороны каждого конвейера.
Блок управления памятью осуществляет двухступенчатое формирование физического адреса ячейки памяти сначала в пределах сегмента, а потом в пределах страницы. Для управления работой внешнего кэша используются специальные аппаратные средства.
Архитектурным нововведением Pentium является специальный режим системного управления (SMM – System Management Mode), который разработан для перевода системы в состояние пониженного энергопотребления. Этот режим не доступен приложениям и управляется программой из ПЗУ на кристалле процессора. В режиме SMM Pentium использует иное, изолированное от других режимов пространство памяти.
Блок ШИ обеспечивает связь процессора с другими устройствами через системную шину, включающую в себя 64-разрядную шину данных и 32-разрядную шину адреса и шину управления. Процессор Pentium поддерживает работу систем с физической памятью до 4 Гбайт.
Развитие процессоров Pentium связано, прежде всего, с совершенствованием технологии их производства, расширением системы команд, совершенствованием алгоритмов предсказания переходов, методов загрузки конвейеров, способов взаимодействия с кэш-памятью.
Отличительной особенностью процессоров Pentium 6-го (Pentium Pro, Pentium II, Pentium III) и 7-го (Pentium IV) поколений от ранних моделей Pentium является иной подход к реализации принципа многооперационной обработки данных. Он заключается в том, что вместо увеличения числа конвейеров исполнения команд, что требует значительных аппаратных затрат, используется один конвейер с большим количеством исполнительных блоков. Например, обработка команд в Pentium IV осуществляется 20-ступенчатым конвейером (гиперконвейером), который условно можно разделить на 3 относительно независимых конвейера:
1) Входной конвейер упорядоченной обработки, который обеспечивает выборку команд из памяти, декодирование их во внутренние RISC-команды и устранение ложных взаимосвязей по данным и ресурсам.
2) Конвейер неупорядоченной обработки, который реализует собственно исполнение команд. При неупорядоченной обработке более интенсивная загрузка конвейеров суперскалярного процессора. Чтобы гарантировать правильное исполнение программы, результаты команд, выполненных вне очереди, должны записываться по целевым адресам в том же порядке, в каком они следуют в исходной программе. Эту работу осуществляет специальный блок процессора – блок временного хранения результатов, выполненных вне очереди.
3) Конвейер вывода результатов исполнения команд, который осуществляет запись результатов в архитектурные регистры процессора и память в порядке, предусмотренном программой.
Эффективная работа гиперконвейера Pentium IV также обеспечивается за счёт спекулятивного исполнения команд, когда для непрерывной загрузки конвейера выполняются действия, не предусмотренные программным кодом.
В блоке предсказания ветвлений используется более совершенный, по сравнению с более ранними моделями процессоров Pentium, алгоритм предсказания ветвлений. Адреса команд переходов и метки ветвлений с подробной предысторией сохраняются в буфере (объёмом 4 Кбайта) блока предсказания ветвлений.
Ещё одним важным отличием процессора Pentium IV от ранних моделей является использование в его структуре вместо кэша команд кэша трасс. Трассы – это последовательности микрокоманд, в которые декодированы команды x86, принадлежащие одной или нескольким ветвям исходной программы. В кэше могут размещаться до 12 Кбайт микрокоманд. В кэш трасс не попадают команды, которые никогда не будут использоваться. Кэш трасс совместно с блоком выборки образуют устройство предварительной обработки.
Использование гиперконвейера, кэша трасс и более производительного исполнительного ядра позволило достигнуть в Pentium IV существенного повышения производительности.
Программная модель процессоров Pentium.
Объединяющей характеристикой рассмотренных микропроцессоров Pentium является то, что все они, несмотря на существенные различия в архитектуре, имеют одинаковую программную модель. Совокупность всех программно доступных регистров процессора образует его программную модель /2/. Она показывает те ресурсы процессора, которыми может пользоваться программист.
Программная модель подразделяется на прикладную и системную. В состав прикладной программной модели (ППМ) процессора входят полный набор регистров, которые доступны прикладным программистам; особенности организации памяти и доступные способы адресации; типы данных и команд. Системная программная модель (СПМ) процессора объединяет его программно доступные системные ресурсы, с помощью которых обеспечивается доступ к встроенным механизмам защиты и многозадачности. СПМ процессора в основном используется системными программистами.
Центральный процессор является ключевым компонентом любого персонального компьютера. В этом материале мы расскажем об основных характеристиках современных процессоров, их технологических особенностях и базовых функциональных возможностях.
Введение
Любое компьютерное устройство, будь то ноутбук, настольный ПК или планшет состоит из нескольких важных компонентов, которые отвечают за его функциональные возможности и работоспособность в целом. Но, пожалуй, самым важным из них является центральный процессор (ЦП, ЦПУ или CPU) - устройство, отвечающее за все основные вычисления и выполняющее машинные инструкции (код программ). Недаром, именно процессор, считается мозгом компьютера и главной частью его аппаратного обеспечения.
Как правило, выбирая себе компьютер, мы в первую очередь обращаем внимание на то, какой именно процессор находится в его основе, так как от его производительности будут напрямую зависеть возможности и функциональность вашего будущего ПК. Именно поэтому, человек, который владеет информацией о современных производителях процессоров и тенденциях развития этого рынка, сможет грамотно определить не только возможности того или иного компьютерного устройства, но и оценить перспективность будущей покупки нового ПК или обновления старого.
Совершенно очевидно, что процессоры, установленные во всевозможных компьютерных и электронных устройствах, отличаются между собой не только своей производительностью, но и конструктивными особенностями, а так же принципами работы. В рамках этого цикла мы с вами будем знакомиться с процессорами, построенными на базе архитектуры x86 , которые лежат в основе большинства современных настольных компьютеров, ноутбуков и нетбуков, а так же некоторых планшетов.
Наверняка, у многих читателей, особенно тех, кто только начинает знакомиться с компьютером, существует определенное предубеждение, что разбираться во всех этих «процессорных премудростях» удел опытных пользователей, потому что это очень сложно. Но так ли все проблематично на самом деле?
С одной стороны, конечно процессор - это очень сложное устройство и досконально изучить все его технические характеристики действительно непросто. Еще больше усугубляет ситуацию тот факт, что количество моделей ЦП, которые вы сможете сейчас найти на современном рынке очень велико, так как одновременно в продаже присутствуют сразу несколько поколений чипов. Но с другой стороны, процессоры имеют всего несколько ключевых характеристик, разобравшись в которых, рядовой пользователь сможет самостоятельно оценить возможности той или иной модели процессора и сделать правильный выбор, не запутавшись во всем модельном разнообразии.
Основные характеристики процессоров
Архитектура x86 впервые была реализована в собственных процессорах компанией Intel в конце 70-ых годов, а в ее основу были положены вычисления со сложным набором команд (CISC). Свое название эта архитектура получила от последних двух цифр, которыми заканчивались кодовые наименования моделей ранних изделий Intel - пользователи со стажем наверняка помнят еще 286-е (80286), 386-е (80386) и 486-е (80486) «персоналки», являвшиеся мечтой любого компьютерщика конца 80-ых, начала 90-ых годов.
На сегодняшний день архитектура x86 была также реализована и в процессорах компаний AMD, VIA, SiS, Cyrix и многих других.
Основными характеристиками процессоров, по которым их принято разделять на современном рынке, являются:
- фирма производитель
- серия
- количество вычислительных ядер
- тип установочного разъема (сокет)
- тактовая частота.
Производитель (бренд) . На сегодняшний день все центральные процессоры для настольных компьютеров и ноутбуков разделены на два больших лагеря под марками Intel и AMD, которые вместе покрывают около 92% общего мирового рынка микропроцессоров. Несмотря на то, что из них доля Intelсоставляет примерно 80%, эти две компании уже много лет с переменным успехом конкурируют между собой, пытаясь завлечь покупателей под свои знамена.
Серия - является одной из ключевых характеристик центрального процессора. Как правило, оба производителя разделяют свою продукцию на несколько групп по их быстродействию, ориентации на разные категории пользователей и различные сегменты рынка. Каждая из таких групп составляет семейство или серию со своим отличительным названием, по которому можно понять не только ценовую нишу продукта, но и в общем, его функциональные возможности.
На сегодняшний день в основе продукции компании Intelлежат пять основных семейств -Pentium (Dual-Core) , Celeron (Dual-Core) , Core i3, Core i5 и Core i7 . Первые три нацелены на бюджетные домашние и офисные решения, два последних лежат в основе производительных систем.
![]()
Процессор Intel Core i7
Несколько особняком от основных семейств держится линейка чипов Atom , отличающаяся от остальных низким энергопотреблением и невысокой стоимостью. Эти процессоры предназначены для установки в бюджетных системах, где не требуется высокая производительность, но необходимо малое потребление энергии. К таковым относятся нетбуки, неттопы, планшетные ПК и коммуникаторы.
Нельзя не упомянуть и еще об одном семействе процессоров компании из Санта-Клара - Core 2 . Не смотря на то, что оно уже не выпускается, и найти его в продаже можно лишь на различных «барахолках», до сих пор, у пользователей это семейство пользуется заслуженной популярностью, а многие нынешние домашние компьютеры оснащены процессорами именно этой серии.
Компания AMD, почитателям своей продукции, предлагает процессоры серий Athlon II , Phenom II , A-Series и FX-Series . Путь двух первых семейств подходит к логическому завершению, последние же два только набирают обороты. Кое-где еще можно встретить в продаже самые бюджетные процессоры Sempron , хотя их дни практически сочтены.

Процессор AMD FX-Series
Как и Intel, AMD имеет тоже свою «мобильную» серию под названием E- series , микропроцессоры которой характеризуются пониженным энергопотреблением и предназначены для установки в недорогие настольные и портативные ПК.
Количество вычислительных ядер . Еще в прошлом десятилетии разделение процессоров по количеству ядер не было вовсе, так как все они были одноядерными. Но времена меняются, и сегодня одноядерные ЦП можно назвать анахронизмом, а на смену им пришли многоядерные собратья. Самыми распространёнными из них являются двух и четырехъядерные чипы. Несколько меньше распространены процессоры с тремя, шестью и восемью вычислительными ядрами.
Наличие в процессоре сразу нескольких ядер призвано увеличить его производительность, и как вы понимаете, чем их больше, тем она выше. Правда при работе со старым, неоптимизированным под многоядерные вычисления, программным обеспечением это правило может и не работать.
Тип разъема . Любой процессор устанавливается в системную плату, на которой для этого существует специальный разъем (гнездо) или по-другому - сокет (Socket). Процессоры разных производителей, серий и поколений устанавливаются в разные типы разъемов. Сейчас, для настольных ПК, таковых семь - четыре для чипов Intel и три для AMD.
Основным и самым распространенным сокетом для центральных процессоров Intel считается LGA 1155. Самые производительные и продвинутые решения этой компании устанавливаются в разъем LGA 2011. Остальные два типа разъемов - LGA 775 и LGA 1156 доживают свои последние дни, так как выпуск процессоров под такие типы сокета практически прекращен.
Среди изделий AMD, на сегодняшний день самым используемым типом разъема можно назвать Socket AM3. Как правило, в него устанавливаются большинство бюджетных и самых ходовых продуктов компании. Правда эта ситуация в ближайшее время скорее всего измениться, так как все новейшие процессоры и производительные решения имеют разъемы Socket AM3+ и Socket FM1.
Кстати процессоры Intelи AMDможно очень просто отличить по одному характерному признаку, который вы возможно уже заметили, смотря на фотографии. Изделия компании AMD имеют на задней части множество штырьков-контактов, с помощью которых они подключаются к системной плате (вставляются в разъем). Intel же использует принципиально иное решение, так как контактные ножки находятся не на самом процессоре, в внутри разъема материнской платы.
Рассматривать разъемы здесь для мобильных решений мы не будем, так как это не имеет никакого практического смысла. Ведь тип сокета для пользователя важен только в том случае, если вы планируете самостоятельно произвести замену (апгрейд) процессора в вашем компьютере. В портативных же устройствах это сделать довольно затруднительно, да и сами мобильные версии процессоров купить в рознице практически невозможно.
Тактовая частота - характеристика определяющая производительность процессора, измеряющаяся в мегагерцах (МГц) или гигагерцах (ГГц) и показывающая то количество операций, которое он может проделать в секунду. Правда, проводить сравнение производительности разных моделей процессоров только по показателю их тактовой частоты в корне неверно.
Дело в том, что для выполнения одной операции, разным чипам может потребоваться разное количество тактов. Кроме того, современные системы при вычислениях используют конвейерную и параллельную обработки, и могут за один такт выполнить сразу несколько операций. Все это приводит к тому, что разные модели процессоров, имеющие одинаковую тактовую частоту, могут показывать совершенно различную производительность.
Сводная таблица семейств процессоров для настольных ПК

Технологический процесс (технология производства)
При производстве микросхем и в частности кристаллов микропроцессоров в промышленных условиях используется фотолитография - метод, которым с помощью литографического оборудования на тонкую кремневую подложку наносятся проводники, изоляторы и полупроводники, которые и формируют ядро процессора. В свою очередь используемое литографическое оборудование имеет определенную разрешающую способность, которая и определяет название применяемого технологического процесса.

Intel
Чем же так важен технологический процесс, с помощью которого изготавливаются процессоры? Постоянное совершенствование технологий позволяет пропорционально уменьшать размеры полупроводниковых структур, что способствует уменьшению размера процессорных ядер и их энергопотребления, а так же снижению их стоимости. В свою очередь снижение энергопотребления уменьшает тепловыделение процессора, что позволяет увеличивать их тактовую частоту, а значит и вычислительную мощность. Так же небольшое тепловыделение позволяет применять более производительные решения в мобильных компьютерах (ноутбуки, нетбуки, планшеты).

Кремниевая пластина с чипами процессоров AMD
Первый процессор Intel с архитектурой x86, до сих пор являющейся основной для всех современных ЦП, был произведен в конце 70-ых годов с помощью техпроцесса равному 3 мкм (микрометра). К началу 2000-ых годов практически все ведущие производители микросхем, включая компании AMD и Intel, освоили 0,13 мкм или 130 нм - технологический процесс. Большинство современных процессоров изготавливаются по 32 нм - техпроцессу, а с середины 2012 года и по 22 нанометровой технологии.
Переход на более тонкий техпроцесс всегда является значимым событием для производителей микропроцессоров. Ведь это, как было отмечено ранее, приводит к снижению стоимости производства чипов и улучшению их ключевых характеристик, а значит, делает выпускаемую продукцию разработчика более конкурентоспособной на рынке.
Энергопотребление и тепловыделение
На ранней стадии своего развития микропроцессоры потребляли совсем небольшое количество энергии. Но с ростом тактовых частот и количества транзисторов в ядре чипов, этот показатель стал стремительно расти. Практически не учитываемый на первых порах фактор энергопотребления на сегодняшний день имеет колоссальное влияние на эволюцию процессоров.
Чем выше энергопотребление процессора, тем больше он выделяет тепла, которое может привести к перегреву и выходу из строя, как самого процессора, так и окружающих его микросхем. Для отведения тепла используются специальные системы охлаждения, размер которых, напрямую зависит от количества выделяемого тепла процессором.
В начале 2000-ых годов тепловыделения некоторых процессоров выросло выше 150 Вт, а для их охлаждения приходилось использовать массивные и шумные вентиляторы. Более того, средняя мощность блоков питания того времени составляла 300 Вт, а это значит что более половины ее должно было уходить на обслуживание «прожорливого» процессора.
Именно тогда стало понятно, что дальнейшее наращивание вычислительной мощности процессоров невозможно без снижения их энергопотребления. Разработчики были вынуждены кардинально пересмотреть процессорные архитектуры и начать активно внедрять технологии, способствующие снизить тепловыделение.
![]()
Процессоры, работающие на сверхвысоких тактовых частотах, приходится остужать вот такими гигантскими системами охлаждения.
Для оценки тепловыделения процессоров была введена величина, характеризующая требования к производительности систем охлаждения и получившая название TDP . TDP показывает на отвод какого количества тепла должна быть рассчитана та или иная система охлаждения при использовании с определенной моделью процессора. Например, TDP процессоров для мобильных ПК должно быть менее 45 Вт, так как использование в ноутбуках или нетбуках больших и тяжелых систем охлаждения невозможно.
На сегодняшний день, в эру расцвета портативных устройств (ноутбуки, неттопы, планшеты), разработчикам удалось добиться колоссальных результатов на поприще снижения энергопотребления. Этому поспособствовали: переход на более тонкий технологический процесс при производстве кристаллов, внедрение новых материалов для снижения токов утечки, изменение компоновки процессоров, применение всевозможных датчиков и интеллектуальных систем, отслеживающих температуру и напряжения, а так же внедрение других технологий энергосбережения. Все эти меры позволяют разработчикам продолжать наращивать вычислительные мощности процессоров и использовать более производительные решения в компактных устройствах.
На практике, учитывать тепловые характеристики процессора при покупке стоит, если вы хотите собрать бесшумную компактную систему, или например, желаете что бы будущий ноутбук работал как можно дольше от аккумулятора.
Архитектура процессоров и кодовые имена
В основе каждого процессора лежит так называемая процессорная архитектура - набор качеств и свойств, присущий целому семейству микрочипов. Архитектура напрямую определяет внутреннюю конструкцию и организацию процессоров.
По сложившейся традиции, компании Intelи AMD дают своим различным процессорным архитектурам кодовые имена. Это более точно позволяет систематизировать современные процессорные решения. Например, процессоры одного семейства с одинаковой тактовой частотой и количеством ядер могут быть изготовлены с применением разного технологического процесса, а значит иметь разную архитектуру и производительность. Так же применение звучных имен в названиях архитектур дает возможность производителям более эффектно презентовать, нам пользователям, свои новые разработки.
Разработки Intel носят географические названия мест (гор, рек, городов и т.д.), находящихся недалеко от мест размещения ее производственных структур, ответственных за разработку соответствующей архитектуры. Например, первые процессоры Core 2 Duo были построены на архитектуре Conroe (Конрой), которая получила свое название в честь города, расположенного в американском штате Техас.
Компания AMD какой-либо четкой тенденции формирования имен для своих разработок не имеет. От поколения к поколению тематическая направленность может изменяться. Например, новые процессоры компании носят кодовые имена Liano и Trinity.
Многоуровневый кэш
В процессе выполнения вычислений, микропроцессору необходимо постоянно обращаться к памяти для чтения или записи данных. В современных компьютерах функцию основного хранения данных и взаимодействия с процессором выполняет оперативная память.
Не смотря на высокую скорость обмена данными между двумя этими компонентами, процессору часто приходиться простаивать, ожидая запрошенную у памяти информацию. В свою очередь это приводит к снижению скорости вычислений и общей производительности системы.
Для улучшения этой ситуации, все современные процессоры имеют кэш - небольшой промежуточный буфер памяти с очень быстрым доступом, использующейся для хранения наиболее часто запрашиваемых данных. Когда процессору становятся необходимы какие-то данные, он сначала ищет их копии в кэше, так как оттуда выборка необходимой информации произойдет гораздо быстрее, чем из оперативной памяти.
Большинство микропроцессоров для современных компьютеров имеют многоуровневый кэш, состоящий из двух или трех независимых буферов памяти, каждый из которых отвечает за ускорения определенных процессов. Например, кэш первого уровня (L1) может отвечать за ускорение загрузки машинных инструкций, второго (L2) - ускорение записи и чтения данных, а третьего (L3) - ускорение трансляции виртуальных адресов в физические.
Одной из самых основных проблем, стоящих перед разработчиками, является нахождение оптимальных размеров кэша. С одной стороны, большой кэш может содержать больше данных, а значит процент того, что процессор найдет среди них нужные - выше. С другой стороны, чем больше размер кэша, тем больше задержка при выборке данных из него.
Поэтому, кэши разных уровней имеют разный размер, при этом кэш первого уровня - самый маленький, но и самый быстрый, а третьего - самый большой, но и самый медленный. Поиск данных в них происходит по принципу от меньшего к большему. То есть процессор сначала пытается найти необходимую ему информацию в кэше L1, затем в L2 и потом в L3 (при его наличии). При отсутствии нужных данных во всех буферах происходит обращение к оперативной памяти.
В целом, эффективность работы кэша, особенно 3-его уровня, зависит от характера обращения программ к памяти и архитектуры процессора. Например, в некоторых приложениях наличие кэша L3 может принести 20%-ый прирост производительности, а в некоторых не сказаться вовсе. Поэтому, на практике вряд ли стоит руководствоваться характеристиками многоуровневого кэша, при выборе процессора для своего компьютера.
Встроенная графика
С развитием технологий производства и как следствие уменьшением размеров чипов, у производителей появилась возможность размещать внутри процессора дополнительные микросхемы. Первой из таковых, стало графическое ядро, отвечающее за вывод изображения на монитор.
Такое решение позволяет снизить общую стоимость компьютера, так как в этом случае нет необходимости использовать отельную видеокарту. Очевидно, что гибридные процессоры ориентированы на использование в бюджетных системах и корпоративном секторе, где производительность графической составляющей вторична.
Первый пример интеграции видеопроцессора в «нормальный» ЦП продемонстрировала компания Intel в начале 2010 года. Конечно, никакой революции это не принесло, так как до этого момента графика уже давно и успешно интегрировалась в чипсеты материнских плат.
Когда-то разница по функционалу между интегрированной и дискретной графикой была принципиальной. На сегодняшний же день можно говорить лишь о разной производительности этих решений, так как встроенные видеочипы способны выводить изображения на несколько мониторов в любых доступных разрешениях, выполнять 3D-ускорение и аппаратное кодирование видео. По сути, интегрированные решения по своей производительности и возможностям можно сравнить с младшими моделями видеокарт.
Компания Intel интегрирует в свои процессоры графическое ядро под незатейливым названием IntelHDGraphics собственной разработки. При этом процессоры Core 2, Celeron и старшие модели Core i7 встроенных графических ядер не имеют.
AMD, осуществив слияние в 2006 году с гигантом по производству видеокарт, канадской компанией ATI, встраивает в свои решения видеочипы семейства Radeon HD. Более того, некоторые новые процессоры компании представляют собой объединение процессорных ядер x86 и графических Radeonна одном кристалле. Единый элемент, созданный путем слияния центрального (CPU) и графического (GPU) процессоров получил название APU, Accelerated Processor Unit (ускоренный процессорный элемент). Именно так (APU) теперь и называют процессоры A и E-серий.
В общем, интегрированные графические решения от компании AMDявляются более производительными, чем Intel HD и выглядят предпочтительнее в игровых приложениях.
Режим Turbo
Многие современные процессоры оснащены технологией, позволяющей им в некоторых случаях автоматически увеличивать тактовую частоту выше номинальной, что приводит к увеличению производительности приложений. Фактически данная технология является «саморазгоном» процессора. Время работы системы в режиме Turbo зависит от условий эксплуатации, рабочей нагрузки и конструктивных особенностей платформы.
Компания Intel в своих процессорах использует собственную технологию интеллектуального разгона под названием Turbo Boost. Используется она в производительных семействах Core i5 и Core i7.
Отслеживая параметры, связанные с нагрузкой на ЦПУ (напряжение и сила тока, температура, мощность), встроенная система управления повышает тактовую частоту ядер в случае, когда максимальный тепловой пакет (TDP) процессора еще не достигнут. При наличии незагруженных ядер они отключаются и освобождают свой потенциал для тех, которые используются приложениями. Чем меньше ядер задействовано в вычислениях, тем выше поднимается тактовая частота чипов, участвующих в вычислениях. Для однопоточных приложений ускорение может составлять 667 МГц.
AMD так же имеет свою технологию динамического разгона наиболее нагруженных ядер и применяет ее только в своих 6 и 8-ядерных чипах, к котором относятся серии Phenom II X6 и FX. Называется она Turbo Core и способна работать только в том случае, если в процессе вычислений количество загруженных ядер составляет меньше половины от их общего числа. То есть в случае 6-ядерных процессоров, число неактивных ядер должно быть не менее трех, а 8-ядерных - четырех. В отличие от Intel Turbo Boost, в этой технологии на прирост частоты не влияет количество свободных ядер и он всегда одинаков. Его величина зависит от модели процессора и колеблется от 300 до 600 МГц.
Заключение
В заключении давайте попробуем применить практически полученные знания с пользой. Например, в одном популярном магазине компьютерной электроники продаются два процессора Intel Core i5 cодинаковой тактовой частотой 2.8 ГГц. Давайте посмотрим на их описания, взятые с сайта магазина, и попробуем разобраться в их отличиях.


Если внимательно посмотреть на скриншоты, то несмотря на то, что оба процессора относятся к одному семейству общего у них не так уж много: тактовая частота, да количество ядер. Остальные характеристика рознятся, но первое на что стоит обратить внимание - это типы разъемов, в которые устанавливаются оба процессора.
Intel Core i5 760 имеет разъем Socket 1156, а значит относится к устаревшему поколению процессоров. Покупка его будет оправдана только в том случае, если у вас уже стоит в компьютере материнская плата с таким гнездом, и менять ее вы не хотите.
Более новый Core i5 2300 произведен уже по более тонкому техпроцессу (32 нм против 45 нм), а значит, имеет и более совершенную архитектуру. Несмотря на несколько меньший L3 кэш и «саморазгон» этот процессор наверняка не уступит в производительности своему предшественнику, а наличие встроенной графики позволит обойтись без приобретения отдельной видеокарты.
Несмотря на то, что у обоих процессоров тепловыделение указано одинаковым (95 Вт), Core i5 2300 в равных условиях будет холоднее своего предшественника, так как мы уже знаем, что более современный технологический процесс обеспечивает меньшее энергопотребление. В свою очередь это увеличивает его разгонный потенциал, что не может не радовать компьютерных энтузиастов.
А теперь давайте рассмотрим пример на базе процессоров AMD. Здесь мы выбрали специально процессоры из двух разных семейств - Athlon II X4 и Phenom II X4. По идее линейка Phenom является более производительной, чем Athlon, но давайте посмотрим на их характеристики и решим, все ли так однозначно.

Из характеристик видно, что оба процессора имеют одинаковые тактовую частоту и количество вычислительных ядер, практически идентичное тепловыделение, а так же у обоих отсутствует встроенное графическое ядро.
Первое различие, которое сразу бросается в глаза - процессоры устанавливаются в разные разъемы. Не смотря на то, что оба они (разъемы) на данный момент активно поддерживаются производителями системных плат, из этой пары Socket FM1 выглядит несколько предпочтительнее с точки зрения будущей модернизации, так как туда можно установить новые процессоры (APU) A-серии.
Еще одним плюсом Athlon II X4 651 является более тонкий и современный технологический процесс, по которому он был произведен. Phenom II отвечает наличием Turbo-режима и кэша третьего уровня.
В итоге, ситуация складывается неоднозначная и здесь ключевым фактором может стать розничная цена, которая у процессора из линейки Athlon II на 20-25% меньше, чем у Phenom II. А с учетом более перспективной платформы (Socket FM1) покупка Athlon II X4 651 выглядит более привлекательной.
Конечно, что бы более однозначно говорить о преимуществах тех или иных моделей процессоров, необходимо знать на базе какой архитектуры они изготовлены, а так же их реальную производительность в различных приложениях, измеренную на практике. В следующем материале, мы рассмотрим подробно современные модельные ряды микропроцессоров Intel и AMD для настольных ПК, познакомимся с характеристиками различных семейств CPU, а так же приведем сравнительные результаты их производительности.
Описание и назначение процессоров
Определение 1
Центральный процессор (ЦП) – основной компонент компьютера, который выполняет арифметические и логические операции, заданные программой, управляет процессом вычислений и координирует работу всех устройств ПК.
Чем мощнее процессор, тем выше быстродействие ПК.
Замечание
Центральный процессор часто называют просто процессором, ЦПУ (Центральное Процессорное Устройство) или CPU (Central Processing Unit), реже – кристаллом, камнем, хост-процессором.
Современные процессоры являются микропроцессорами.
Микропроцессор имеет вид интегральной схемы – тонкой пластинки из кристаллического кремния прямоугольной формы площадью в несколько квадратных миллиметров, на которой размещены схемы с миллиардами транзисторов и каналов для прохождения сигналов. Кристалл-пластинка помещен в пластмассовый или керамический корпус и соединен золотыми проводками с металлическими штырьками для подсоединения к системной плате ПК.
Рисунок 1. Микропроцессор Intel 4004 (1971 г.)

Рисунок 2. Микропроцессор Intel Pentium IV (2001 г.). Слева – вид сверху, справа – вид снизу
ЦП предназначен для автоматического выполнения программы.
Устройство процессора
Основными компонентами ЦП являются:
- арифметико-логическое устройство (АЛУ) выполняет основные математические и логические операции;
- управляющее устройство (УУ), от которого зависит согласованность работы компонентов ЦП и его связь с другими устройствами;
- шины данных и адресные шины ;
- регистры , в которых временно хранится текущая команда, исходные, промежуточные и конечные данные (результаты вычислений АЛУ);
- счетчики команд ;
- кэш-память хранит часто используемые данные и команды. Обращение в кэш-память гораздо быстрее, чем в оперативную память, поэтому, чем она больше, тем выше быстродействие ЦП.

Рисунок 3. Упрощенная схема процессора
Принципы работы процессора
ЦП работает под управлением программы, которая находится в оперативной памяти.
АЛУ получает данные и выполняет указанную операцию, записывая результат в один из свободных регистров.
Текущая команда находится в специальном регистре команд. При работе с текущей командой значение так называемого счетчика команд увеличивается, который затем указывает на следующую команду (исключением может быть только команда перехода).
Команда состоит из записи операции (которую нужно выполнить), адресов ячеек исходных данных и результата. По указанным в команде адресам берутся данные и помещаются в обычные регистры (в смысле не в регистр команды), получившийся результат тоже сначала помещается в регистр, а уж потом перемещается по своему адресу, указанному в команде.
Характеристики процессора
Тактовая частота указывает частоту, на которой работает ЦП. За $1$ такт выполняется несколько операций. Чем выше частота, тем выше быстродействие ПК. Тактовая частота современных процессоров измеряется в гигагерцах (ГГц): $1$ ГГц = $1$ миллиард тактов в секунду.
Для повышения производительности ЦП стали использовать несколько ядер, каждое из которых фактически является отдельным процессором. Чем больше ядер, тем выше производительность ПК.
Процессор связан с другими устройствами (например, с оперативной память ю) через шины данных, адреса и управления. Разрядность шин кратна 8 (т.к. имеем дело с байтами) и отличается для разных моделей, а также различна для шины данных и шины адреса.
Разрядность шины данных указывает на количество информации (в байтах), которое можно передать за $1$ раз (за $1$ такт). От разрядности адресной шины зависит максимальный объем оперативной памяти, с которым может работать ЦП.
От частоты системной шины зависит количество данных, которые передаются за отрезок времени. Для современных ПК за $1$ такт можно передать несколько бит. Важна также и пропускная способность шины, равная частоте системной шины, умноженной на количество бит, которые можно передать за $1$. Если частота системной шины равна $100$ Мгц, а за $1$ такт передается $2$ бита, то пропускная способность равна $200$ Мбит/сек.
Пропускная способность современных ПК исчисляется в гигабитах (или десятках гигабит) в секунду. Чем выше этот показатель, тем лучше. На производительность ЦП влияет также объем кэш-памяти.
Данные для работы ЦП поступают из оперативной памяти, но т.к. память медленнее ЦП, то он может часто простаивать. Во избежание этого между ЦП и оперативной памятью располагают кэш-память, которая быстрее оперативной. Она работает как буфер. Данные из оперативной памяти посылаются в кэш, а затем в ЦП. Когда ЦП требует следующее данное, то при наличии его в кэш-памяти оно берется из него, иначе происходит обращение к оперативной памяти. Если в программе выполняется последовательно одна команда за другой, то при выполнении одной команды коды следующих команд загружаются из оперативной памяти в кэш. Это сильно ускоряет работу, т.к. ожидание ЦП сокращается.
Замечание 1
Существует кэш-память трех видов:
- Кэш-память $1$-го уровня самая быстрая, находится в ядре ЦП, поэтому имеет небольшие размеры ($8–128$ Кб).
- Кэш-память $2$-го уровня находится в ЦП, но не в ядре. Она быстрее оперативной памяти, но медленнее кэш-памяти $1$-го уровня. Размер от $128$ Кбайт до нескольких Мбайт.
- Кэш-память $3$-го уровня быстрее оперативной памяти, но медленнее кэш-памяти $2$-го уровня.
От объема этих видов памяти зависит скорость работы ЦП и соответственно компьютера.
ЦП может поддерживать работу только определенного вида оперативной памяти: $DDR$, $DDR2$ или $DDR3$. Чем быстрее работает оперативная память, тем выше производительность работы ЦП.
Следующая характеристика – сокет (разъем), в который вставляется ЦП. Если ЦП предназначен для определенного вида сокета, то его нельзя установить в другой. Между тем, на материнской плате находится только один сокет для ЦП и он должен соответствовать типу этого процессора.
Типы процессоров
Основной компанией, выпускающей ЦП для ПК, является компания Intel. Первым процессором для ПК был процессор $8086$. Следующей моделью была $80286$, далее $80386$, со временем цифру $80$ стали опускать и ЦП стали называть тремя цифрами: $286$, $386$ и т.д. Поколение процессоров часто называют семейством $x86$. Выпускаются и другие модели процессоров, например, семейства Alpha, Power PC и др. Компаниями-производителями ЦП также являются AMD, Cyrix, IBM, Texas Instruments.
В названии процессора часто можно встретить символы $X2$, $X3$, $X4$, что означает количество ядер. Например в названии Phenom $X3$ $8600$ символы $X3$ указывают на наличие трех ядер.
Итак, основными типами ЦП являются $8086$, $80286$, $80386$, $80486$, Pentium, Pentium Pro, Pentium MMX, Pentium II, Pentium III и Pentium IV. Celeron является урезанным вариантом процессора Pentium. После названия обычно указывается тактовая частота ЦП. Например, Celeron $450$ обозначает тип ЦП Celeron и его тактовую частоту – $450$ МГц.
Процессор нужно устанавливать на материнскую плату с соответствующей процессору частотой системной шины.
В последних моделях ЦП реализован механизм защиты от перегрева, т.е. ЦП при повышении температуры выше критической переходит на пониженную тактовую частоту, при которой потребляется меньше электроэнергии.
Определение 2
Если в вычислительной системе несколько параллельно работающих процессоров, то такие системы называются многопроцессорными .
Технические характеристики аппаратных компонентов определяют пределы возможностей компьютера. Сердцем любого компьютера является процессор. Наиболее доступные характеристики процессора – это его марка и тактовая частота .
Теоретически, марка определяет фирму, которая разработала и изготовила процессор, а тактовая частота дает оценку его производительности. Например, процессор маркирован как Pentium 4 – 1,6 ГГц. Здесь Pentium-4 - марка процессора. Модель выпускается фирмой Intel. Значение 1,6 ГГц – это тактовая частота, которая указывается в мегагерцах или гигагерцах. Например, при тактовой частоте в 1ГГц процессор способен изменить свое состояние миллиард раз за одну секунду. Такты - это кванты времени процессора. Любая выполняемая операция занимает целое число тактов, и в каждом такте процессор может начать выполнение только одной операции. Если два процессора различаются только тактовой частотой, то их производительность в отсутствие внешних задержек пропорциональна частоте.
Говоря о тактовой частоте процессора, часто употребляют термин "внутренняя частота ". Процессор устанавливается на материнскую плату, поэтому частота его работы задается извне. Стандартные частоты материнской платы – 66; 100 и 133 МГц – намного меньше, чем тактовые частоты современных процессоров. Но процессор устроен таким образом, что каждый внешний такт преобразуется в несколько внутренних в соответствии с заданным коэффициентом умножения . Сегодня рост производительности процессоров обеспечивается как раз увеличением этого коэффициента. Впервые коэффициент внутреннего умножения частоты появился в процессорах i80486, где он имел значение 2 – 3 при внешней частоте 33 – 40 МГц.
У современных процессоров коэффициент умножения намного выше (до 24 у Pentium 4). Но предельная производительность работы достигается только в том случае, когда процессор выполняет все операции "внутри себя". Даже обмен данными с оперативной памятью в этом случае превращается в тормозящий фактор, не говоря уже о взаимодействии с другими устройствами.
| Год выпуска | Тип CPU | Разрядность (бит) | Адресное прост-во | ТЧ | Дополнительные характеристики | |||
| Внутр. | ШД | ША | ||||||
| i8086 | 1 Мбайт | 4,77 МГц | Технология 3 мкм, 29000 транзисторов. | |||||
| Сопроцессор i8087 | ||||||||
| i8088 | 1 Мбайт | 4,77 МГц | ||||||
| Сопроцессор i8087. С этого процессора началась история IBM PC (август 1981г.). Принцип обратной программной совместимости – старые программы должны работать на новых процессорах. На выполнение каждой инструкции уходило в среднем по 12 тактов процессорного ядра. В состав процессоров включен блок предварительной выборки команд из памяти. | ||||||||
| i80286 | 16 Мбайт | 6; 8; 10; 12 МГц | Технология 1,5 мкм, 134000 транзисторов. | |||||
| Сопроцессор i80287. Работа в защищенном режиме, позволяющем использовать виртуальную память размером до 1 Гбайта. Защищенный режим не нашел массового применения, процессоры использовались в основном как "очень" быстрые i8086. На выполнение инструкций уходило в среднем по 4,5 такта. | ||||||||
| i80386 | 4 Гбайт | 8-40 МГц | Технология 1,5 мкм, 275000 транзисторов. | |||||
| i80386SX | 4 Гбайт | |||||||
| Сопроцессор i80387. 32-разрядная архитектура (IA-32). Существенно доработан защищенный режим. Введен режим V86 и страничное управление памятью. Возможность работы с 64Тбайтами виртуальной памяти. i80386SL – процессор с пониженным энергопотреблением. | ||||||||
| i80486DX | 4 Гбайт | 20-120 МГц | Технология 1 мкм, 1,2 млн транзисторов. | |||||
| i80486DX2 | ||||||||
| i80486SX | ||||||||
| В архитектуре процессора были использованы элементы высокопроизводительных процессоров RISC. Основные операции выполняет RISC-ядро, "задания" для которого готовят из входных CISC-инструкций х86. На выполнение одной инструкции уходило в среднем 2 такта. Последовательность выполнения команд была изменена, режимы декодирования и исполнения могли работать одновременно, что позволяло выполнять многие команды всего за один такт. Это была первая серия процессоров, у которых блок вычислений с плавающей точкой (FPU) находился с ядром процессора на одном кристалле, что и обеспечило значительный прирост производительности. Intel486 имел внутреннюю кэш-память первого уровня объемом 8 Кбайт, в которой хранились последние используемые команды. К ним обеспечивался очень быстрый доступ. Более дешевый 486SX продавался с отключенным блоком вычислений с плавающей точкой. | ||||||||
1993 год - Intel Pentium
1995 год - Intel Pentium PRO
1997 год - Intel Pentium MMX
1997 год - Intel Pentium II
1999 год - Intel Pentium III
2000 год - Intel Pentium 4
2007 год - Intel Core
Intel 8086 (1978) . Относится в 16-разрядным процессорам 1-го поколения. БИС МП микропроцессора с геометрическими размерами 5,5х5,5мм имеет 40 контактов, содержит около 29000 транзисторов и потребляет 1.7 Вт от источника питания +5В, тактовая частота 5,5; 8 или 10 МГц.
МП выполняет операции над 8- и 16-разрядными данными, представленными в двоичном и двоично-десятичном виде. Он имеет встроенные аппаратные средства умножения и деления.
МП имеет внутреннее сверхоперативное запоминающее устройство емкостью 14х16 байт. Шина адреса является 20-разрядной, что позволяет непосредственно адресовать 2 20 =1048576 ячеек памяти (1 Мбайт). ШД=16 бит.
Пространство адресов ввода-вывода составляет 64 Кбайт. В БИС Intel 8086 реализована многоуровневая векторная система прерываний с количеством векторов до 256. Предусмотрено также организация прямого доступа к памяти.
Среднее время выполнения команды занимает 12 тактов. Особенностью МП является возможность частичной реконфигурации аппаратной части для обеспечения работы в двух режимах – минимальном и максимальном . Режимы работы задаются аппаратно. В минимальном режиме , используемом для построения однопроцессорных систем, МП самостоятельно формирует все сигналы управлениявнутренним системным интерфейсом. Максимальный режим используется для построения мультипроцессорных систем.
Сопроцессор i8087.
Intel 8088 (1979). Отличается от МП Intel 8086 тем, что имеет внешнюю 8-разрядную шину данных при внутренней 16-разрядной шине. Уменьшение разрядности ШД упрощает построение блоков памяти интерфейса с внешними устройствами, но производительность процессора снижается на 20-30%. Структурная схема Intel 8088 аналогична схеме Intel 8086, однако, длина очереди команд сокращена до 4 байт. С программной точки зрения процессоры идентичны, их система команд и набор регистров одинаковы. Сопроцессор i8087.
Intel 80286 (1982). П ринадлежит ко 2-му поколению16-разрядных МП. Он выполнен по технологии 1,5 мкм, содержит 134 тыс. транзисторов работает с тактовой частотой 12,5 МГц. За счет усовершенствованной архитектуры быстродействие МП в 6 раз выше, чем i8086 с тактовой частотой 5 МГц. Разрядность регистров равна 16. ША 24-разрядная, что позволяет адресовать 16Мбайт памяти. ШД= 16 бит. Пространство адресов ввода-вывода составляет 64Кбайт. Система команд содержит все команды i8086, несколько новых команд общего назначения и группу команд управления защитой данных. МП имеет специальные средства для работы в системах с многими пользователями и в многозадачных режимах. Его наиболее существенным отличием от МП i8086/88 является механизм управления адресацией памяти, который обеспечивает 4-уровневую систему защиты данных и поддержку виртуальной памяти. Специальные средства предназначены для поддержки механизма переключения задач. МП имеет средства контроля перехода через границу сегмента, работающие в реальном режиме.
МП может работать в двух режимах:
8086 – реальный режим;
Защищенный режим (давал возможность запускать программы в отдельных сегментах памяти, что исключало их взаимное влияние).
Переключение в защищенный режим осуществляется быстро – одной командой, а в режим реальной адресации медленно – лишь через аппаратный сброс процессора. В MS-DOS используется реальный режим.
Был использован в ПК серии IBM PC/AT, он быстро установил новый стандарт мощности и производительности.
Сопроцессор i80287.
Intel 80386 (1985 год). Первый 32-разрядный процессор. Выполнен по 1,5 мкм технологии и содержит 275тыс. транзисторов. Разрядность регистров, ША, ШД равна 32. Емкость прямо адресуемой памяти составляет 4 Гбайт. Процессор может работать в 3-х режимах:
Реальном;
Защищенном;
Режиме виртуального процессора V86 (позволяло одному процессору запускать несколько программ реального режима как отдельные "виртуальные машины"). Другими словами, стандартные приложения DOS могли работать одновременно, причем считалось, что каждое из них имеет доступ ко всей памяти в 1 Мбайт.
Возможна параллельная работа нескольких виртуальных процессоров 8086 под управлением ОС защищенного режима. Переключение режимов происходит быстрее, чем в МП i80286. Процессор имеет механизмы страничной адресации, которые существенным образом повышают эффективность работы с памятью свыше 1 Мбайта. Очередь команд составляет 16 байт. МП имеет модификации DX – с 32-разрядными регистрами, ШД и ША; SX – с внешней 16-разрядной ШД и 24-разрядной ША; SL – отличается от модификации SX сниженным энергопотреблением и встроенным контроллером внешней кэш-памяти на 16 - 64 Кбайт.
Благодаря схеме адресации памяти, названной виртуальной, вся используемая процессором память могла превышать физический размер памяти компьютера. Процессор автоматически перемещал содержимое временно не используемых участков памяти на жесткий диск и предоставлял эту память другим программа. Именно этот процессор помог системе Microsoft Windows 3.0 достичь грандиозной популярности. ОС Windows позволяла пользователям работать и в защищенном, и в виртуальном режимах. В виртуальном режиме можно было запускать несколько больших приложений одновременно. Сопроцессор i80387.
Intel 80486 (1989г.). Характеризуется значительно более высоким быстродействием по сравнению с i80386. Он выполнен по 1 мкм технологии и содержит 1,2 млн транзисторов. Основные особенности МП – наличие внутренней кэш-памяти первого уровня объемом 8 Кбайт (для хранения последних используемых команд); встроенного арифметического сопроцессора, совместимого по командам с сопроцессором i80387. В МП i80486 увеличена очередь команд, ускорено выполнение операций, как в целочисленном АЛУ, так и в блоке арифметического сопроцессора, используется умножение тактовой частоты системной платы. В модификациях 486DX2 внутренняя частота равна удвоенной внешней, а в МП 486DX4 кратность может быть 2; 2,5; 3. В модификациях SX и в некоторых модификациях SL арифметический сопроцессор отсутствует. Процессоры DX4 в зависимости от модификации могут работать при питании 5В и 3,3В и имеют режим управления системой энергопотребления. Начиная с МП i486, применяется внутреннее раздельное кэширование команд и данных.
В архитектуре процессора были использованы элементы высокопроизводительных процессоров RISC. Последовательность выполнения команд была изменена, режимы декодирования и исполнения могли работать одновременно, что позволяло выполнять многие команды всего за один такт. Это была первая серия процессоров, у которых блок вычислений с плавающей точкой находился с ядром процессора на одном кристалле, что и обеспечило значительный прирост производительности.
Pentium I – первые процессоры семейства P5 (март 1993 г.). Тогда Intel решила дать своему изделию имя, которое впоследствии стало нарицательным. Первое поколение Pentium носило кодовое имя P5, а также i80501, напряжение питания было 5 В, расположение выводов – "матрица", тактовые частоты – 60 и 66 МГц, технология изготовления – 0,80-микронная, частота шины равна частоте ядра. Процессоры содержали более 3.1 млн. транзисторов и выпускались по технологии 0.80 мкм, а позже – 0.60 мкм. Размер кэша первого уровня L1 составлял 16 Кб: 8 Кб на данные и 8 Кб на инструкции. Впервые она была разделена – 8 Кбайт на данные и 8 Кбайт на инструкции. Кэш второго уровня размещался на материнской плате и мог иметь объем до 1 Мб. Процессор выпускался для разъема Socket 4.
 |  |  |
Согласно проведенным тестам, производительность процессора Pentium с ТЧ 90МГц почти вдвое превышала производительность процессоров i486. Pentium мог выполнять более одной команды за такт, потому что в нем использовалась суперскалярная архитектура с двумя конвейерами для команд. Другими словами, две команды могли одновременно декодироваться и выполняться. Конвейеры были надежным и испытанным способом повышения производительности, так как они уже давно использовались в процессорах архитектуры RISC для рабочих и графических станций. Способствовали успеху Pentium и такие особенности, как:
- встроенная кэш-память для команд и данных (отдельно) объемом по 8 Кбайт каждая;
- улучшенный блок конвейерных вычислений с плавающей точкой;
- блок предсказаний адреса перехода (предсказания ветвлений) позволял процессору анализировать последовательность команд. Когда встречались команды условия (например, цикл или команда условного перехода), процессор рассчитывал наиболее вероятный адрес очередной последовательности команд и загружал их для выполнения;
- он имел 32-разрядную шину адреса и 64-разрядную шину данных для внешних устройств;
- два 32-разрядных целочисленных АЛУ;
- буфера выборки с опережением.
Безусловно, Pentium стал большим шагом вперед. Тактовая частота первых процессоров 66МГц, но она быстро достигла отметки в 400 МГц.
Pentium MMX (P55, январь 1997 г.) стали следующими процессорами фирмы Intel. ориентированные на мультимедийное, 2D- и 3D-графическое и коммуникационное применения. В его архитектуру дополнительно введены:
Восемь 64-разрядных ММХ- регистров;
4 новых типа данных;
Улучшенная логика предсказания переходов;
Расширенная конвейеризация;
Более глубокая буферизация памяти (удвоенный размер буфера отложенной памяти);
6-ступенчатые конвейеры.
Технология – 0,35 мкм. Напряжение питания ядра уменьшилось до 2,8 В. Процессоры потребовали изменения в архитектуре материнских плат, так как двойное электропитание потребовало установки дополнительного стабилизатора напряжения. Объем кэш-памяти L1 был увеличен в два раза и составил 32 Кбайта. Внутренняя тактовая частота – 166-233 МГц, частота шины – 66 МГц. Рассчитаны на Socket 7. Стали последними в линейке процессоров Pentium для компьютеров Desktop.
 |  | |
Pentium Pro – первые процессоры шестого поколения, выпущенные в ноябре 1995 г. Впервые применена кэш-память L2, объединенная в одном корпусе с ядром и работающая на частоте ядра процессора. Процессоры имели очень высокую себестоимость изготовления. Выпускались сначала по технологии 0,50 мкм, а затем по 0,35 мкм, что позволило увеличить объем кэш-памяти L2 с 256 до 512, 1024 и 2048 Кбайт. Тактовая частота – от 150 до 200 МГц. Частота шины – 60 и 66 МГц. Кэш-память L1 – 16 Кбайт (2x8Кб). Разъем Socket 8. Поддерживали все инструкции процессоров Pentium, а также ряд новых инструкций (cmov, fcomi и т.д.). В дальнейшем все новшества унаследовали Pentium II. Архитектура Pentium Pro значительно опередила свое время.
Применено динамическое выполнение команд, т.е. комбинация средств предсказания множественных ветвлений, анализа прохождения данных и виртуального выполнения, при котором в процессоре команды могут выполняться не в таком порядке, как предусмотрено программным кодом. При этом команды, которые не зависят от результатов предыдущих операций, могут выполняться в измененном порядке, но последовательность записи результатов в память и порты будет соответствовать начальному программному коду. Возможность выполнения команд с опережением (спекулятивное выполнение ), переупорядочивание команд в случае, если команда в одном конвейере будет выполнена быстрее, чем предшествующая во втором конвейере, и предсказание переходов при динамическом выполнении повышает производительность вычислений. Архитектура процессора позволяет объединение в симметричную мультипроцессорную систему до 4-х процессоров на одной шине.
Важным отличием процессора является архитектура двойной независимой шины . Системная шина (frontside bus – шина переднего плана) работает на частоте материнской платы, чтосущественно снижает эффективное быстродействие ПК. С КЭШем L2 процессор обменивается информацией по высокоскоростной шине backside bus – шине заднего плана, отделенной от системной шины. Наличие отдельной шины заднего плана значительно ускоряет обмен с кэш-памятью, т.к. она работает на ТЧ процессора. Такое разделение шин позволяет в три раза ускорить обмен процессора с памятью.
 |  |  |
Pentium II - первые процессоры с названием Pentium II появились 7 мая 1997 года. Эти процессоры объединяют архитектуру Pentium PRO и технологию MMX.
В МП Pentium PRO и Pentium II появилась качественно новая перспектива – начались внедряться SIMD-инструкции (Single instruction multiply data), в которых одно и тоже действие может совершаться над многими данными.
По сравнению с Pentium Pro удвоен размер первичного кэша (16 Кб + 16 Кб). В процессоре используется новая технология корпусов - картридж с печатным краевым разъемом, на который выведена системная шина: S.E.C.C (Single Edge Contact Cartridge). Выпускался в конструктиве Slot 1, что естественно потребовало апгрейда старых системных плат. На картридже размером 14 x 6.2 x 1.6 см установлена микросхема ядра процессора (CPU Core), несколько микросхем, реализующих вторичный кэш, и вспомогательные дискретные элементы (резисторы и конденсаторы).
 |  |  |
Такой подход можно считать шагом назад – у Intel уже была отработана технология встраивания в ядро кэша второго уровня. Но таким образом можно было использовать микросхемы памяти сторонних производителей. В свое время, Intel считала такой подход перспективным на ближайшие 10 лет, хотя через непродолжительное время отказывается от него.
В то же время сохраняется независимость шины вторичной кэш-памяти, которая тесно связана с ядром процессора собственной локальной шиной. Частота этой шины была вдвое меньше частоты ядра. Так что Pentium II имел большой кэш, работающий на половинной частоте процессора.
Первые процессоры Pentium II (кодовое название Klamath), появившиеся 7 мая 1997 года, насчитывали около 7.5 млн. транзисторов только в процессорном ядре и выполнялись по технологии 0.35 мкм. Они имели тактовые частоты ядра 233, 266 и 300 МГц при частоте системной шины 66 МГц. При этом вторичный кэш работал на половинной частоте ядра и имел объем 512 Кб. Для этих процессоров был разработан Slot 1, по составу сигналов сильно напоминающий Socket 8 для Pentium Pro. Однако Slot 1 позволяет объединять лишь пару процессоров для реализации симметричной мультипроцессорной системы, либо системы с избыточным контролем функциональности (FRC). Так что этот процессор представляет собой более быстрый Pentium Pro с поддержкой MMX, но с урезанной поддержкой мультипроцессорности.
26 января 1998 году вышел процессор из линейки Pentium II с названием ядра – Deschutes. От Klamath отличался более тонким технологическим процессом – 0.25 мкм и частотой шины 100 МГц. Имел тактовые частоты 350, 400, 450 МГц. Выпускался в конструктиве S.E.C.C, который в старших моделях был сменен на S.E.C.C.2 - кэш с одной стороны от ядра, а не с двух, как в стандартном Deschutes и измененное крепление кулера. Последнее ядро, официально применявшееся в процессорах Pentium II, хотя последние модели Pentium II 350-450 шли с ядром, уже больше напоминавшим Katmai - только, естественно, с обрезанным SSE. Осталась поддержка MMX. Кэш первого уровня – все те же 32 Кб (16 + 16). Кэш второго уровня также не изменился – 512 Кб работающие на половинной частоте. Процессор состоял из 7.5 млн. транзисторов и выпускался для разъема Slot 1.
Pentium II OverDrive – так назывался процессор вышедший 11 августа 1998 года для апгрейда Pentium PRO на старых материнских платах, и работающий в разъеме Socket 8). Носил кодовое имя P6T. Имел частоту 333 МГц. Кэш первого уровня – 16 Кб на данные + 16 Кб на инструкции, кэш второго уровня имел размер 512 Кб и был интегрирован в ядро. Работал на частоте процессора. Шина 66 МГц. Содержал 7.5 млн. транзисторов и производился по техпроцессу 0.25 мкм. Поддерживал набор инструкций MMX.
Celeron - новой веткой в направлении технологии микропроцессоров для Intel был выпуск параллельных основным, "облегченных" и удешевленных вариантов. Таковой является серия Celeron. 15 апреля 1998 года был представлен первый процессор, носящий название Celeron и работающий на тактовой частоте 266 МГц.
Кодовое имя Covington. Этот процессор является “обрезанным” Pentium II. Celeron построен на базе ядра Deschutes без кэша второго уровня. Что, конечно же, сказалось на его производительности. Зато разгонялся он просто великолепно (от полутора до двух раз). Если разгон Pentium II ограничивала максимальная частота кэша, то здесь его просто не было!
Celeron работал на шине 66 МГц и повторял все основные характеристики своего предка – Pentium II Deschutes: кэш первого уровня – 16 Кб + 16 Кб, MMX, техпроцесс 0.25 мкм. 7.5 млн. транзисторов. Процессор выпускался без защитного картриджа - конструктив – S.E.P.P (Single Edge Pin Package). Разъем - Slot 1.
Начиная с частоты 300 МГц, появились процессоры Celeron с интегрированным в ядро кэшем второго уровня, работающим на частоте процессора, размером 128 Кб. Кодовое имя – Mendocino. Вышел 8 августа 1998. Благодаря полноскоростному кэшу имеет высокую производительность, сравнимую с Pentium II (при условии одинаковой частоты системной шины). Выпускались с тактовыми частотами от 300 до 533 МГц. 30 ноября 1998 года, вышел вариант процессора с конструктивом P.P.G.A (Plastic Pin Grid Array), который работал в разъеме Socket 370.
 |  |  |  |
До 433 МГц выпускался в двух конструктивах: S.E.P.P и P.P.G.A. Некоторое время параллельно существовали Slot-1 (266 - 433 МГц) и Socket-370 (300A - 533 МГц) варианты, в конце концов, первый был плавно вытеснен последним.
Новый Celeron был шагом к Pentium III , но так как работал на шине 66 МГц, не мог показать все преимущества интегрированного высокоскоростного кэша. Так как кэш был интегрирован в ядро, значительно увеличилось количество транзисторов, из которых состоит процессор - 19 млн. Техпроцесс остался прежним – 0.25 мкм.
XEON - для мощных компьютеров предназначено семейство Xeon. Pentium II Xeon - серверный вариант процессора Pentium II, пришедший на смену Pentium PRO. Производился на ядре Deschutes и отличался от Pentium II более быстрой (полноскоростной) и более емкой (есть варианты с 1 или 2 Мб) кэш-памятью второго уровня и конструктивом. Выпускался в конструктиве S.E.C.C для Slot 2. Это тоже краевой разъем, но с 330 контактами, регулятором напряжения VRM, запоминающим устройством EEPROM. Способен работать в мультипроцессорных конфигурациях. Был выпущен 29 июня 1998 года.
Кэш второго уровня, как и в Pentium PRO, полноскоростной. Только здесь он находится на одной плате с процессором, а не интегрирован в ядро. Кэш первого уровня – 16 Кб + 16 Кб. Частота шины – 100 МГц. Поддерживал набор инструкций MMX. Процессор работал на частотах 400 и 450 МГц. Выпускался с применением техпроцесса 0.25 мкм. и содержал 7.5 млн. транзисторов.
 |   |
На этом развитие линейки Pentium II заканчивается. Начиная с Pentium II, Intel выделяет три основных направления в производстве процессоров: Pentium – высокопроизводительный процессор для рабочих станций и домашнего применения, Celeron – бюджетный вариант пентиума для офиса или дома, Xeon – серверный вариант, обладающий повышенной производительностью.
Pentium III - первые процессоры с названием Pentium III мало чем отличались от Pentium II. Главное отличие – основанное на новом блоке 128-разрядных регистров расширение набора SIMD-инструкций (70 новых команд), ориентированных на форматы данных с плавающей запятой – SSE Streaming SIMD Extentions). При выполнении операции над двумя регистрами, фактически МП оперирует 4-мя парами чисел. Благодаря этому МП может выполнять до 4-операций одновременно, что является полезным при работе с:
Трехмерной графикой и моделированием с использованием вычислений в формате с плавающей точкой;
Обработкой сигналов и моделированием процессов с широким диапазоном изменения параметров;
Генерацией трехмерных изображений в программах реального времени;
Алгоритмами кодирования и декодирования видеосигналов с блочной обработкой;
Числовыми алгоритмами цифровой фильтрации, которые работают с потоками данных.
Они работали на такой же шине с частотой 100 МГц (позже, с 27 сентября 1999 года, появились модели, работающие на шине 133 МГц), выпускались в конструктиве S.E.C.C. 2 и были рассчитаны на установку в Slot 1.
 |  |
Кэш память осталась прежней: L1 – 16 Кб + 16 Кб. L2 – 512 Кб, размещенные на процессорной плате, и работающие на половинной частоте процессора. Главным отличием является расширение набора SIMD-инструкций - SSE (Streaming SIMD Extensions). Также расширен набор команд MMX и усовершенствован механизм потокового доступа к памяти. Кодовое имя ядра Katmai. Вышел 26 февраля 1999 года. Процессор работал на частотах 450-600 МГц, содержал 9.5 млн. транзисторов. Также как предшественник - Pentium II Deschutes, выпускался с применением техпроцесса 0.25 мкм.
Coppermine – так называлось следующее ядро процессора Pentium III, пришедшее на смену Katmai 25 октября 1999 года. По сути, именно Coppermine является новым процессором, а не доработкой Deschutes. Новый процессор имел полноскоростной интегрированный в ядро кэш второго уровня размером 256 Кб (Advanced Transfer Cache).
Выпускался с использованием техпроцесса 0.18 мкм. Утоньшение технологии с 0.25 до 0.18 мкм позволило разместить на ядре большее число транзисторов и теперь их стало 28 млн., против 9.5 млн. в старом Katmai. Правда, основная масса нововведенных транзисторов относится к интегрированному L2-кэшу. L1 кэш остался без изменений. Поддерживал наборы команд MMX и SSE. Сначала выпускался в конструктиве S.E.C.C. 2, но так как кэш теперь встроен в ядро процессора, процессорная плата оказалась ненужной, и только повышала стоимость процессора. Поэтому вскоре процессоры стали выходить в конструктиве FC-PGA (Flip-Chip PGA). Как и Celeron Mendocino, они работали в разъеме Socket 370.
 |  | |
Правда со старыми материнскими платами была ограниченная совместимость. Так как теперь процессор работал на более высоких тактовых частотах, ядро было расположено сверху, и имело непосредственный контакт с радиатором. Coppermine был последним процессором для Slot 1. Работал на шине 100 и 133 МГц (в названии процессора 133-я шина обозначалась буквой B, например – Pentium III 750B). Процессоры с ядром Coppermine работали на тактовых частотах с 533 до 1200 МГц. Первые попытки выпустить процессор на этом ядре с частотой 1113 МГц закончились неудачей, так как он в предельных режимах работал очень нестабильно, и все процессоры с этой частотой были отозваны - этот инцидент сильно подмочил репутацию Intel.
Ядро Tualatin пришло на смену Coppermine 21 июня 2001 года. В это время на рынке уже присутствовали первые процессоры Pentium 4 , и новый процессор был предназначен для испытания новой 0.13 мкм. технологии, а также для того чтобы заполнить нишу высокопроизводительных процессоров, так как производительность первых Pentium 4 была довольно низкой. Tualatin - это изначальное название глобального проекта Intel по переводу производства процессоров на 0.13-микронную технологию . Сами процессоры с новым ядром стали первыми продуктами, появившимися в рамках этого проекта.
Изменений в самом ядре немного - добавилась только технология "Data Prefetch Logic". Она повышает производительность, предварительно загружая данные, необходимые приложению в кэш. Кроме этого отличие этих ядер заключается в используемой технологии производства - Coppermine изготавливается по технологии 0.18 мкм, а Tualatin по 0.13 мкм. Разъем для нового процессора остался прежним - Socket 370, а вот конструктив сменился на FC-PGA 2, который использовался в процессорах Pentium 4. От старого FC-PGA он в первую очередь отличается тем, что ядро покрыто теплорассеивающей пластиной, которая также защищает его от повреждения при установке радиатора.
С выпуском Tualatin, линейка Pentium III "распалась" на два класса - настольных и серверных процессоров. У первых объем L2-кэша так и остался равным 256 Кб, у вторых - удвоился до 512 Кб; также у настольной версии нового P-III (так называемого Desktop Tualatin) отсутствовала поддержка SMP . Кэш первого уровня – 16 Кб + 16 Кб. Следует сказать, что Desktop Tualatin просуществовал недолго: он поставлялся только крупным сборщикам ПК, и был изъят с рынка, для того чтобы не составлять конкуренцию Pentium 4. А вот Pentium III-S, серверная версия процессора, должен был занять нишу мощных серверных процессоров, так как производительности процессоров Xeon уже не хватало, а Pentium 4 не имел поддержки SMP, да и вообще показывал довольно низкую производительность.
Как уже было сказано выше, процессоры Tualatin выпускались с применением более совершенного 0.13 мкм. техпроцесса, работали на шине с частотой 133 МГц и состояли из 44 млн. транзисторов. Поддерживали наборы инструкций MMX и SSE. Процессор работал на частотах от 1 ГГц до 1.33 ГГц (Desktop Tualatin), и от 1.13 ГГц до 1.4 ГГц (серверный вариант).
Pentium 4 – следующие после Coppermine принципиально новые IA-32 процессоры Intel для обычных PC. Процессор имеет площадь кристалла 217 мм 2 , потребляет 52Вт при частоте 1500 МГц, содержит 42 млн. транзисторов, 0.18-микронная технология.Вместо традиционных GTL+ и AGTL+ используется новая системная шина Quad Pumped 100 МГц , обеспечивающая передачу данных с частотой 400 МГц и передачу адресов с частотой 200 МГц. Кэш-память L1 – 8 Кбайт.
В архитектуру введен ряд усовершенствований, направленных на увеличение тактовой частоты и производительности:
Добавлены 144 новые потоковые инструкции, расширяющие набор SIMD-инструкций, ориентированных на форматы данных с плавающей запятой. Модуль вычислений с плавающей запятой и потоковый модуль оптимизированы для работы с аудио- и видеопотоками, в том числе 3D-технологиями;
Имеется кэш L2 размером 256Кб, который работает на полной частоте МП и использует встроенную программу коррекции ошибок, обслуживается быстродействующей 256-разрядной шиной (32байта), работающей также на частоте МП;
Улучшена система динамического исполнения команд, что связано с наличием 20 ступеней конвейера, суперскалярной архитектуры, улучшенного предсказания ветвлений программы при условных передачах управления и параллельного «по предположению» (опережающего, спекулятивного) исполнения команд по нескольким предполагаемым путям ветвления;
Новая технология ускоренных вычислений использует два быстрых АЛУ, работающих на удвоенной частоте процессора, которые выполняют короткие арифметические и логические операции за 0,5 такта. Третье, медленное АЛУ, исполняет длинные операции (умножение, деление и др.);
Все новые процессоры Pentium 4 имеют микроархитектуру Intel Net Burst, поддерживающую ряд инновационных возможностей:
- технологию НТ;
- технологию гиперконвейерной обработки данных;
- частоту системной шины 800, 5433 или 400 МГц;
- кэш-память первого уровня с отслеживанием выполнения команд;
- расширенные функции выполнения операций с плавающей запятой и мультимедийных операций;
- набор потоковых SIMD-расширений SSE2 (добавлены новые 144 инструкции) или SSE3 (13 новых инструкций), повышающих производительность при работе с видео- и аудио-информацией. В том числе с речью и графикой.
Технология НТ (Hyper Treading) реализует многопотоковое исполнение программы: на одном физическом процессоре можно одновременно исполнять два задания или два потока команд одной программы (операционные системы «видят» два логических процессора вместо одного). Иначе говоря, эта технология на базе одного МП формирует два или более логических процессора, работающих параллельно и, в известной степени, независимо. НТ обеспечивает повышение производительность до 30% в многозадачных средах и при исполнении программ, которые допускают многопотоковое исполнение.
Технология гиперконвейерной обработки. Повышает пропускную способность конвейера, обеспечивая увеличение производительности и ТЧ. Так, один из основных конвейеров МП – конвейер предсказания ветвлений имеет глубину конвейерной обработки в 31 шаг (против 20 шагов в Pentium 4 с суперконвейерной обработкой).
Кэш L1 с отслеживанием выполнения команд. Поддерживается увеличенный до 16 Мб объем кэш-памяти данных и кэш-памяти команд, которая хранит до 12 000 микроопераций в порядке их выполнения. Это повышает производительность МП, в частности, из-за быстрого доступа к командам ветвления и ускоренного возврата из ветвлений, которые были неверно спрогнозированы.
Соревнуясь с AMD, Intel представила систему модельных номеров, которая позволит искусственно завышать производительность для потребителя. К примеру, линейке Celeron назначены номера 300, а Pentium 4 - 500.
21 февраля 2005 Intel представила 600-ю линейку процессоров, где размер кэша L2 был увеличен с 1 до 2 Мбайт. На основе планов Intel, эта линейка должна была заканчиваться 3,8-ГГц Pentium 4 680. Но, опять же, Intel решила отойти на шаг назад и выпустила в качестве топовой модели 3,6-ГГц Pentium 4 660.
Pentium 4 660 работает на 200 МГц медленнее, чем топовая модель линейки 500, причём задержка CAS кэша L2 была немного увеличена из-за его размера. В итоге процессор не слишком хорошо показывает себя в тестах. Кроме того, пользователям придётся поглубже залезать в свой карман - из-за увеличившегося числа транзисторов новые процессоры оказались дороже.
Параллельно с выпуском линейки 600 Intel представила новую версию Extreme Edition Pentium 4. Ядро процессора идентично линейке 6xx, однако шина FSB работает на 266 МГц (FSB1066). В результате, тактовая частота нового процессора составила 3,73 ГГц. Эффективная шина северного моста, с теоретической пропускной способностью 8,5 Гбайт/с, не слишком выигрывает из-за возросшего размера кэша L2. Производительность Extreme Edition, который на 133 МГц быстрее, не слишком превосходит Pentium 4 660. А цена сохранениа на уровне старого Extreme Edition.
В качестве общего обновления процессоров для Socket 775, 600-я линейка и процессор Extreme Edition получили 64-битные расширения EMT 64 (расширенная технология работы с 64-битовой памятью, она позволила увеличить объем адресного пространства до 2 Тбайт), бит запрета выполнения вредоносного кода NX и поддержку Speedstep. Если процессор загружен не на 100%, технология Speedstep снижает множитель до x14, чтобы уменьшить тепловыделение. Многие производители материнских плат поддерживают эту функцию, позволяя принудительно выставить x14 и "разогнать" процессор по FSB. Таким образом, повышая частоту FSB у Pentium 4 660 до 266 МГц, мы получаем Extreme Edition. Предусмотрен новый стандарт шины PCI Express и работа с микросхемами памяти типа DDR2.
2005г – первый выпуск многоядерных процессоров – Pentium D, Pentium EE 820, Pentium EE 830, Pentium EE 840. Имеют два процессорных ядра аналогичных, используемому в Pentium Extreme Edition . Каждое процессорное ядро имеет кэш L2 объемом 1 Мб. ТЧ – 2.8-3.2 Ггц.
Первые модели на основе ядра Willamette с тактовой частотой 1,4-1,5 ГГц выпущены 20 октября 2000 года, созданны по технологии 0,18 мкм. Разъем – Socket 423. Последняя модель рассчитана на частоту 2 ГГц, после чего ядро Willamette сменяет Northwood.
Prescott - наследник ядра Northwood, изготавливается по 90 нм технологии, частота FSB=667 MHz (166 MHz QPB), поддержка Hyper-Threading, Socket 478.
Развитие: Tejas, Nahalem - 65 нм техпроцесс.
Foster – кодовое наименование ядра и процессоров Pentium 4 в серверном варианте, построенных по идеологии и архитектуре Willamette. Тактовая частота – 100 МГц при передаче данных с частотой 400 МГц. Как и в случае с Cascades, объем кэша L2 остался тем же, что у Willamette. Основные отличия Foster от обычных Pentium 4 на ядре Willamette заключаются в поддержке двухпроцессорных конфигураций и использовании разъема Socket 603. Тактовая частота первых процессоров Xeon на ядре Foster начинается от 1,7 ГГц. Основу систем составят чипсеты i860 и GC-HE от ServerWorks.
Prestonia – кодовое наименование ядра и процессоров Pentium 4 в серверном варианте, созданных по технологии 0,13 мкм . Продолжение линейки Xeon. Микроархитектура NetBurst.
Gallatin – кодовое наименование ядра и процессоров, 0,13 мкм – развитие ядра Foster.
Merced – кодовое наименование ядра и первого процессора архитектуры IA-64, аппаратно совместим с архитектурой IA-32. Включает трехуровневую кэш-память объемом 2-4 Мбайт. Производительность примерно в три раза выше, чем у Tanner. Технология изготовления – 0,18 мкм, частота ядра – 667 МГц и выше, частота шины – 266 МГц. Превосходит Pentium Pro по операциям FPU в 20 раз. Физический интерфейс – Slot M. Поддерживает MMX и SSE. Официальное наименование – Itanium .
McKinley – кодовое наименование ядра и моделей второго поколения процессоров архитектуры IA-64. Тактовая частота ядра процессоров начинается с 1 ГГц.
Itanium 2 –64-разрядный процессор, ранее известный под кодовым наименованием McKinley. Itanium 2 работают на частоте 1 ГГц, обладают 3 Мб кэша L3.
Madison – преемник McKinley. Построен по медной, 0,13 мкм технологии. Тактовые частоты первых процессоров Madison и Deerfield как минимум, 1,5 ГГц, при этом оба чипа имеют 6 Мб кэша L3.
Deerfield – кодовое наименование ядра и процессоров. Ядро является преемником Foster. Процессоры рассчитаны на Slot M и позиционируются как недорогие процессоры архитектуры IA-64 для рабочих станций и серверов среднего уровня.
Montecito - двухядерный чип на базе архитектуры IA-64.